
分布式架构-事务-本地事务
本地事务
什么是事务
事务是解决数据一致性(Consistency) 问题的一种机制
根据数据源的数量, 将一致性分成了单一数据源情况下的”内部一致性“, 多数据源情况下的”外部一致性“.
内部一致性
通过ACID机制来保证数据源内部一致性, 其中AID是手段, C是目的
- 原子性 (Atomic): 在一个事务中对于数据的修改要不全部成功, 要不全部失败回滚
- 持久性 (Duration): 事务提交以后, 对于数据的修改不会出现丢失和撤销
- 隔离性 (Isolation): 多个事务并发执行的时候, 每个事务之间的读, 写操作都相互隔离
- 一致性 (Consistency): 事务前后, 数据满足完整性约束, 数据库保持一致状态
外部一致性
将一致性从”是/否”的二元属性, 拓展成了多元的”强一致性, 最终一致性, 弱一致性”划分, 通过额外的架构手段来在确保代价可承受的条件下获得强度尽可能高的一致性 (XA, TCC, AT, SEGA…)
本节只讨论本地事务, 也就是数据源怎么获取内部一致性, 怎么实现的AID.
实现原子性和持久性
实现原子性和持久性的核心是实现事务数据落盘过程的崩溃恢复机制
- 事务提交前: 部分数据已经落盘后崩溃, 恢复以后会失去原子性(只完成了一部分事务)
- 事务提交后: 部分数据还没有落盘的时候崩溃, 在恢复以后就会失去事务的持久性(只持久化了一部分事务)
Commit Logging
创建一个redo log文件,
- 事务开启的时候写入事务ID,
- 在事务执行修改语句的时候, 将修改的内容, 修改在什么页, 磁盘的什么位置等修改的全部内容都记录在日志里面. 这个过程采取追加写的形式(顺序写效率最高).
- 在事务提交的时候, 写入Commit Record.
- 将日志文件中的记录的修改落盘
- 全部落盘以后写入End Record标志着事务持久化结束
这个过程是怎么解决上面的两种崩溃情况的恢复问题的
如果事务还没有提交, 因为还没有写入Commit Record, 不会执行到落盘过程, 也就没有部分数据落盘的问题. 崩溃恢复以后检测到该事务ID没有对应的Commit Record, 不做处理.
如果事务已经提交了,但是部分数据没有落盘. 崩溃恢复以后, 检测到该事务写入了Commit Record但是没有写入End Record. 这个时候重新执行落盘过程, 因为redo log中记录的是物理上在磁盘什么位置将A修改成B, 所以是幂等的.
Write Ahead Logging
Commit Logging方案只能在事务提交后将数据落盘, 磁盘的IO压力是集中的, 如果在事务执行的过程中磁盘的压力很小, 我们也不能将数据落盘. 所以我们需要一种能在事务提交前, 允许数据提前写入的方案, 这就是WAL.
WAL在Commit Logging的基础上, 增加了另一种Undo Log日志类型, 在执行数据提前落盘的时候, 必须先写入到Undo Log里面, 注明修改了哪个位置的数据, 从什么值改到了什么值. 以便在崩溃恢复以后, 根据Undo Log撤销已经落盘的提前写入的数据, 回滚事务. WAL在崩溃恢复的时候执行以下三个阶段的操作:
- 分析阶段: 从最后一次的检查点(Checkpoint, 在这个点之前的所有的事务都已经完成并且正确地持久化了)开始扫描, 找出来所有没有写入End Record的事务.
- Redo阶段: 如果事务没有End Record但是有Commit Record, 说明事务已提交未完全写入, 根据Redo Log重新落盘. 完成落盘以后在Redo Log中追加上End Record. 移动Checkpoint
- Undo阶段: 如果事务没有End Record也没有Commit Record, 说明事务没有提交, 这个时候根据Undo Log将提前写入的数据修改回去. 完成事务的回滚, 保证了原子性.
实现隔离性
实现隔离性本质上是在解决并发问题, 怎么在并发下实现对数据的串行访问, 很明显, 加锁同步
锁机制
三种锁
- 写锁: 排它锁, 只有持有写锁的事务能执行修改, 数据加了写锁以后, 其他没有持有锁的事务不能写入数据, 不能加读锁
- 读锁: 共享锁, 只有持有读锁的事务能读当前数据, 数据加了读锁以后, 其他事务不能再加写锁, 但是能加读锁.
- 范围锁: 对某个范围加排它锁
事务的隔离级别本质上是加了不同的锁, 实现了不同严格程度的串行化访问.
读未提交: 在修改数据的时候, 为数据加上写锁, 在事务结束的时候释放. 访问数据的时候不加读锁. 会有脏读问题, 事务能读到未提交事务的修改.读提交: 修改数据的时候为数据加上持续到事务结束的写锁, 读数据的时候加上持续到语句结束的读锁. 会有不可重复读的问题, 在同一个事务中, 两次对同一行数据的查询得到了不同的结果集.可重复读: 修改数据的时候为数据加上持续到事务结束的写锁, 读数据的时候加上持续到事务结束的读锁. 会有幻读问题, 在一个事务中, 两次完全相同的范围查询得到了不同的结果集.可串行化: 单行读操作会加读锁, 修改操作会加写锁, 范围读操作加上范围锁. 三个锁的持续范围都是整个事务.
与其说是不同的隔离级别有不同的锁设置, 不如说隔离级别是各种锁在不同加锁时间上组合应用产生的结果, 以锁为手段实现隔离性才是数据库表现出来不同隔离级别的根本原因
MVCC
MVCC(Multi-Version Concurrency Control)并发版本控制. 脏读, 不可重复读, 幻读三个现象的出现都是因为”一个事务读+一个事务写”的情况的出现, MVCC是针对这种情况, 对于读操作的无锁优化方案. 基本思路是执行修改操作的时候不会覆盖掉原来的数据, 而是产生一个新版副本和老版本共存, 在读取的时候根据隔离级别和事务ID决定读哪个版本.
- 在修改数据数据时候, 在记录里面写入修改数据的事务ID, 这个事务ID就是这个数据的版本.
- 事务ID是一个严格递增的数字
- 通过Undo Log将记录的不同版本按照修改顺序串联起来
在有一个事务要读取数据的时候, 通过隔离级别来决定读哪个版本
可重复读: 读取版本(事务ID)小于等于自己的事务ID的记录, 如果有多条记录读取最新的.读提交: 直接读最新版本的数据就好了.
在MySQL-InnoDB下的实现
原子性和持久性
MySQL采用的是WAL策略, 维护了Redo Log和Undo Log, 其中值得注意的是
- Undo Log是存在Buffer Pool中的, 并且它的修改也会被存在Redo Log里面(Undo Log也需要持久化)
- Redo Log有一个专门的buffer, 所有对redo log的修改会先写入到buffer中, 然后再写入到redo log文件中, 并且Redo Log是一个文件组, 有两个文件, 交替写, 一个满了写另一个. 在两个都满了的时候会将MySQL阻塞, 将Buffer Pool中的数据落盘, 并移动checkpoint.
隔离性
锁
MySQL在可重复读隔离级别就引入了间隙锁(范围锁的实现, 一样的功能). 在可重复隔离级别上就基本解决了幻读问题. 但是并不是完全解决了.
情景1: 范围型当前读引起的幻读问题
- 事务A:
SELECT * FROM users WHERE age > 20 FOR UPDATE - 事务B: 插入
age=25的新记录并提交 - 事务A: 同样的查询语句, 会多出一条记录
这个问题是因为第一条当前读语句加的读锁不是范围锁, 只会锁上所有查到的已经存在的行, 但是无法组织其他事务在查询范围内插入新行. 如果是可串行化隔离级别, 在范围读的时候就会加上范围锁了.
情景2: 快照读引起的幻读问题
- 事务A:
SELECT * FROM users WHERE age > 20;(快照读,返回2条记录)。 - 事务B:插入
age=25并提交。 - 事务A:执行
UPDATE users SET status=1 WHERE age > 20;(更新操作触发当前读,将事务B插入的记录纳入更新)。 - 事务A:再次查询时看到新增记录 (幻读)
本质是新提交的记录并没有被加上任何锁. 在事务A执行修改操作以后创建了事务A的新版本的记录, 这个时候快照读通过MVCC会可以读到一个版本号 == 事务A的事务ID的记录
MVCC
通过ReadView记录当前事务ID(creator_trx_id)和已经提交的事务最大ID(min_trx_id). 通过Undo Log形成版本链.
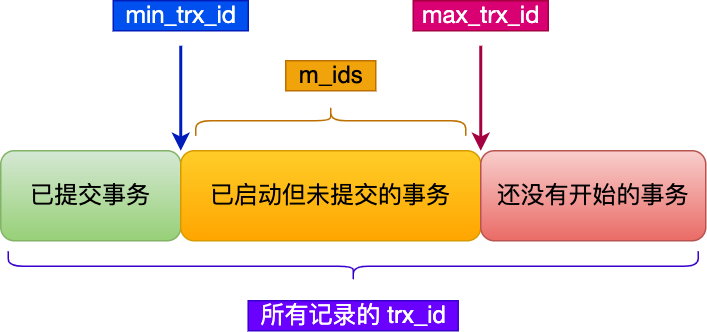
可重复读: 在事务开始的会创建一个ReadView, 读记录的时候会找到 min_trx_id < trx_id < creator_trx_id的记录. 在事务启动以后开始并提交的事务对于当前事务来说就是不可见的了. 它们的新版本的数据的trx_id > ReadView中的creator_trx_id.读提交: 在读执行前创建一个ReadView, 这个时候就能读到其他事务已经提交了的最新数据. 因为这个时候创建ReadView中的min_trx_id就是最新的已经提交的事务的ID.