
操作系统进程加载(ELF)-Linux进程加载启动原理
Linux进程加载启动原理
可执行文件格式
这里讲的都是linux中的可执行文件的格式, 不同的操作系统中的可执行文件的格式是不一样的, 这也是你在不同的平台上编译出来的可执行文件是不能跨平台执行的. 也是为什么如果要跨平台运行其他平台的可执行文件需要转义中间层.
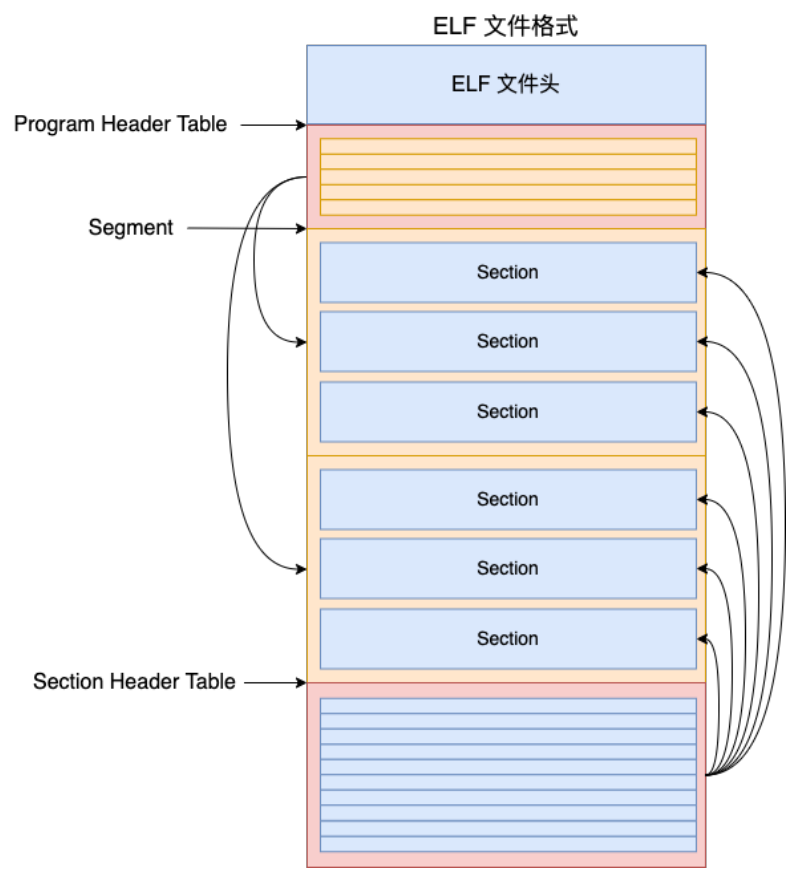
Linux中的可执行文件是ELF(Executable and Linkable Format)文件, 其组成可以分成
- ELF文件头
- Program Header Table
- Segment
- Section
- Section Header Table
下面查看的都是该程序的编译后的ELF文件
1 |
|
ELF文件头
记录了整个文件中的属性信息, 可以通过下面的命令查看
1 | readelf --file-header <file> |
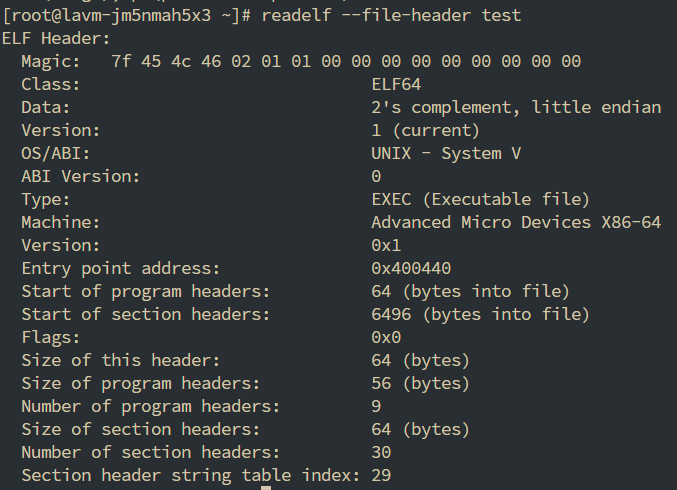
可以看到前面的魔数用于标识这个文件是什么格式的文件
对于ELF的整体的描述:
- Type: 有多种ELF文件, 比如动态链接库等, 其中EXEC格式的才是可执行文件
- OS/ABI: 记录的操作系统的信息
- Machine: 机器的CPU的位数
- Entry point address: 程序的入口地址(往往不是main函数的地址), 这里是0x400440
关于program headers和section headers的描述
- Start of program headers: program header的入口地址
- Start of section headers: section header的入口地址
- Size of this header: ELF文件头的大小
Program Header Table
ELF文件中最重要的组成单位是一个个的Section, 每一个Section都是由编译链接器生成的, 都有不同的用处, 编译器会将我们写的代码的编译后放入到.text Section中, 将全局变量放入到 .data Section或者是.bss Section中
但是对于操作系统来说, 它并不关注具体的Section中的内容是什么, 只关注这块内容以何种权限加载到内存中, 读, 写, 执行等权限属性. 因此编译器将具有相同权限的Section组合成一个Segment, 以便操作系统更快的加载
Program Header Table记录了对于Segment的描述, 通过下面的命令查看
1 | readelf --program-headers (-l) <file> |
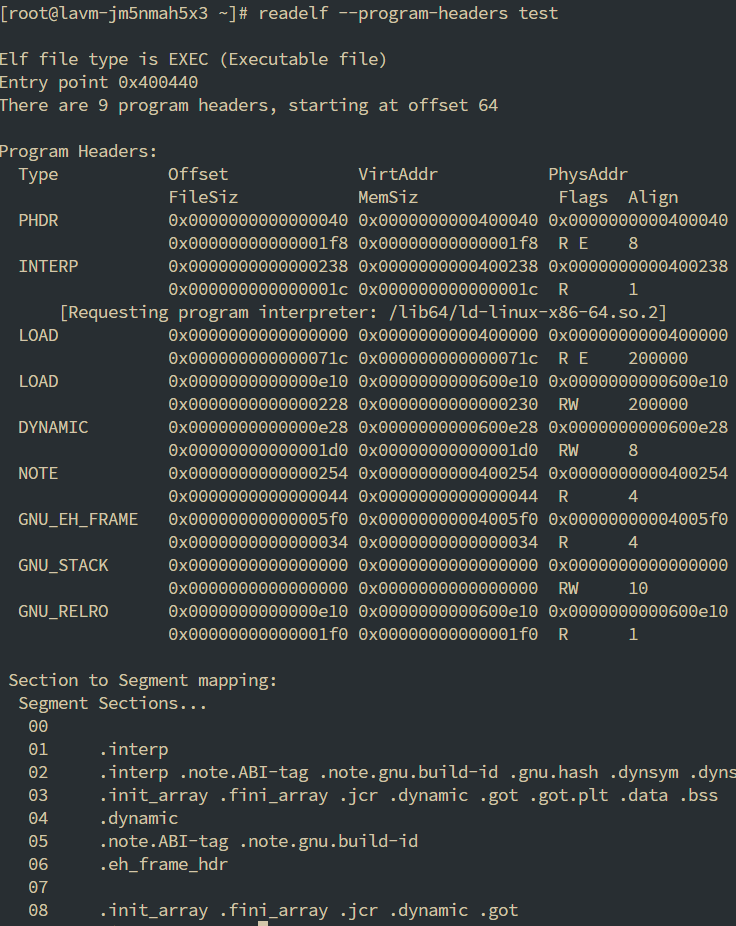
通过下面的Section to Segment mapping能查看到为我们的这个程序有9个Segment, 每个Segment里面放了哪些Section
上面的信息记录了每个Segment的一些信息
- Offset: 该Segment在二进制文件中的起始地址
- VirtAddr: 表示加载到虚拟内存中后的地址
- FileSiz: 当前段的大小
- Flag: 当前段的权限类型, E表示可执行, R表示可读, W表示可写
Section Header Table
记录的自然就是Section的一些信息, 通过下面的命令查看
1 | readelf --section-headers <file> |
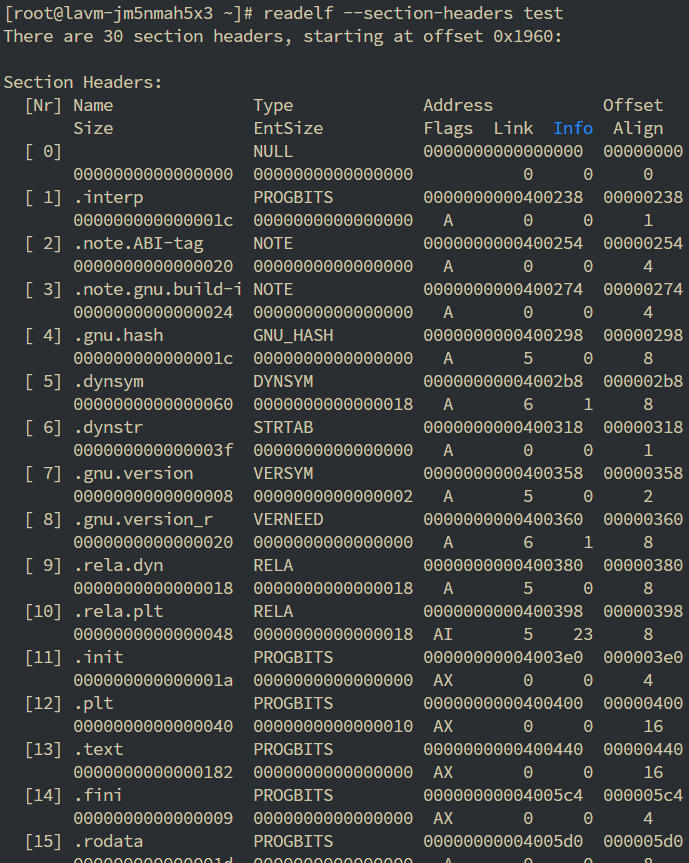
- offset: 当前的Section在二进制文件中的位置
这是权限flag的描述
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
 能看到我们程序中的各种信息放在的位置, 其中.text存放了我们编译后的代码
能看到我们程序中的各种信息放在的位置, 其中.text存放了我们编译后的代码
1 |
|
入口进一步查看
我们前面看到程序的入口是 0x401040, 我们能借助nm命令进一步查看可执行文件中的符号及其地址信息
1 | nm -n <file> |
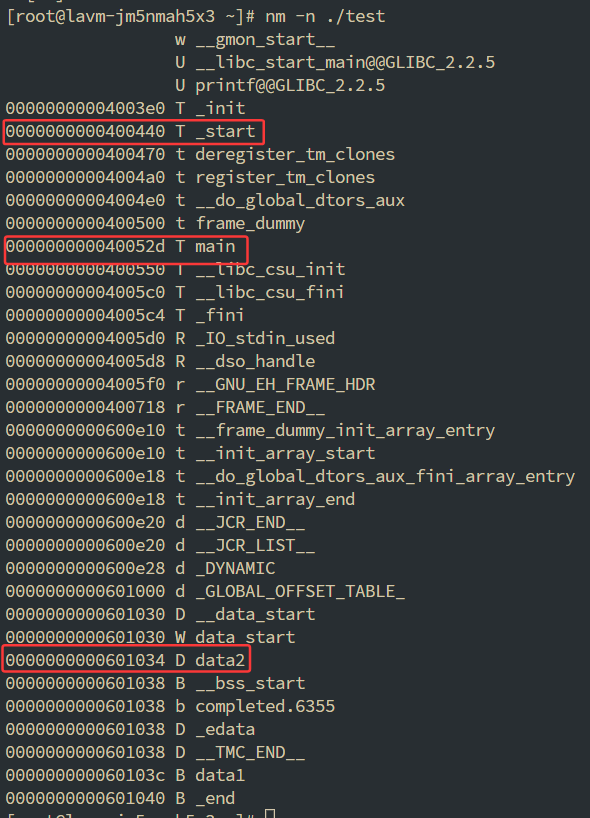
我们能看到0x400440是_start的地址, 并且还能看到data2和data1, 以及main函数的地址
其中_start是glibc的库函数, 是一个汇编函数, 一开始执行了一些寄存器和栈操作, 然后进入到__libc_start_main进行程序的启动
这个函数中做了一些准备工作将argc, argv, 程序的构造函数__libc_csu_init, 析构函数__libc_csu_fini和main函数都通过参数传递给__libc_start_main
最后进入到generic_start_main中完成进入main
加载并启动用户进程
shell启动用户进程
在编译完程序以后, 下一步就是将这个程序启动起来, 一般来说我们都是通过shell将我们的程序启动, shell启动程序一般来讲是通过fork + execve的形式来加载并运行程序的.
1 | int main(int argc, char * argv[]) { |
通过fork创建一个子进程, 然后子进程通过exrcve系统调用启动我们要运行的用户进程
Linux可执行文件加载器
Linux上并不是只能运行ELF文件, 在启动的时候, Linux会将自己支持的所有可执行文件类型的解析器都加载上, 并使用一个formats双向链表将它们保存起来
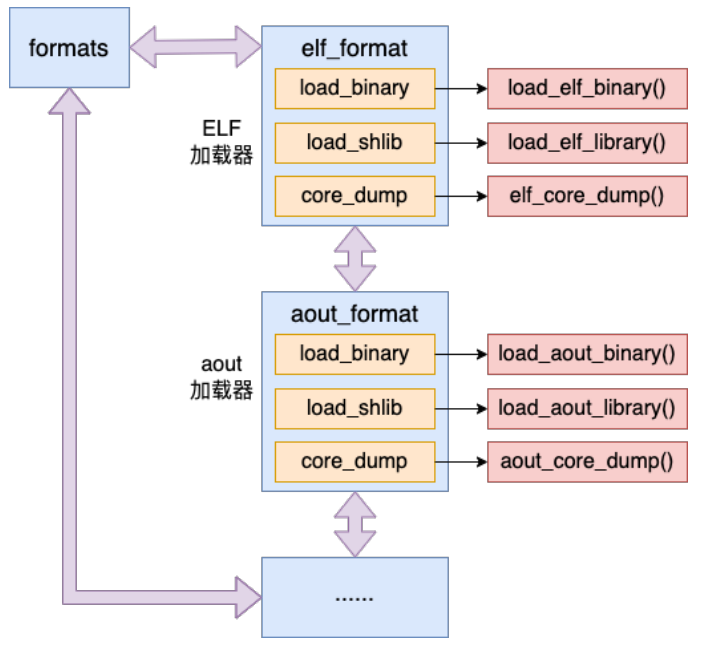
Linux中支持的可执行文件格式有三类
- ELF
- aout: 主要是为了和以前兼容, 不支持动态链接, 被ELF取代
- EM86: 主要作用是Alpha主机上运行Intel的二进制文件
我们这里主要探讨ELF的加载器elf_format
Linux中每一个加载器都通过一个linux_binfmt结构来表示, 其中规定了load_binary函数指针, 加载崩溃文件的core_dump函数指针等.
然后在elf_format中将这些函数指针指向具体的elf的加载函数, 比如load_binary指向的就是load_elf_binary函数, 这个函数也是ELF加载的入口
1 | struct linux_binfmt { |
加载器在初始化的时候会通过register_binfmt函数进行注册, 将加载器挂载到全局加载器列表formats全局链表中
execve加载用户程序
execve是一个系统调用, 执行到的核心函数是do_execve(getname(filename), argv, envp);, 其中的filename是要执行的ELF文件的名字, argv是参数列表, envp是环境变量. 在do_execve中进入到do_execve_common函数
1 | // file:fs/exec.c |
执行的核心步骤是
- 申请并初始化linux_brpm对象
- 然后通过bprm_execve读取可执行文件的文件头128字节, 并选择加载器
alloc_brpm初始化linux_binprm对象
在这个函数中主要做了
- 调用
kzalloc为brpm申请内存 - 然后调用
brpm_mm_init对新申请出来的对象进行初始化- 申请一个全新地址空间的mm_struct对象
- 调用
__brpm_mm_init申请一个页的进程栈内存(也就是申请了一个4KB的VMA), 会把栈的指针记录到bprm->p中
这里的linux_binprm bprm内核对象是一个进程加载的过程中的临时对象, 在加载进程的时候保存加载二进制文件使用的参数等信息, 以及保存为新进程申请的虚拟地址空间, 新进程的栈也会在这个时候申请并交给它保存一会儿, 等进程加载就绪的时候, 这个数据结构就没什么用了
bprm_execve执行加载
会进入到search_binary_handler函数
- 通过文件头, 判断要加载的可执行文件的格式
- 寻找合适的加载器, 尝试加载
这里详细说明下是怎么寻找合适的加载器的, 抽象的来了, Linux是遍历formats链表中所有已经注册的加载器, 尝试对当前文件加载, 如果加载成功了就return, 不然就下一个加载器, 虽然有点低效, 但是确实是这么运行的
ELF文件加载过程
现在我们已经找到了elf_format加载器, 并且将args和env以及要加载的文件还有mm以及一个栈区都准备好了, 我们要正式开始加载这个文件了.
要执行的核心函数就是load_binary指向的load_elf_binary
读取文件头
前面do_execve函数的开头调用的do_execve_common中, 已经将ELF文件头 读取到bprm->buf中了, 所以这里直接拷贝访问这段内存就好了
解析完了以后, 对头部进行一系列的合法性的判断, 如果不合法直接就退出
合法则申请interp_elf_ex对象
读取Progarm Header
读取完文件头以后就是读记录了Segment信息的Program Header
根据文件头的信息, 得出Program Header的数量以及大小, 然后计算出来需要申请多大的内存将program header保存起来并返回, 这里是保存到elf_phdata中(这里是通过kmalloc在伙伴系统中直接分配物理内存, 不会触发缺页中断)
清空父进程继承来的资源
在fork系统调用创建出来的进程中, 包含了很多原进程的信息, 比如打开的文件描述符, 老的地址空间, 信号表等, 这些在新的程序运行时没有用, 需要清空一下
这里是在load_elf_binary中调用begin_new_exec来清空父进程继承来的资源, 这个函数执行的内容是
- 确保文件表不共享
- 释放掉所有旧的mmap, 并替换成新的在bprm->mm
- 确保信号表不共享
然后再将新的栈也设置到新进程上
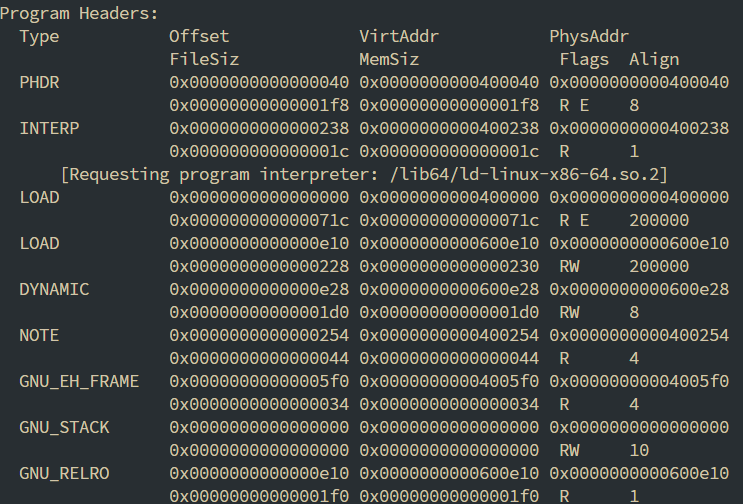
执行Segment加载
接下来, 加载器会将ELF文件中LOAD类型的Segment都加载到内存中来, 使用elf_map在虚拟空间中为其分配地址, 等访问的时候发生缺页中断加载磁盘文件中的代码或数据. 计算start_code, start_data等mm_struct所需要的各个的成员地址, 最后设置虚拟地址空间中的代码段.
只有LOAD类型的Segment是需要被映射到内存中的
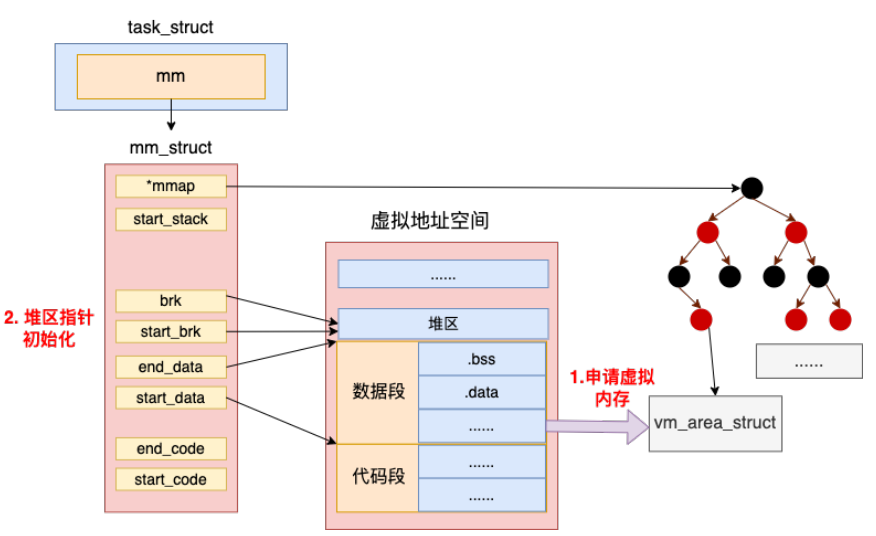
数据内存申请&堆初始化
在load_elf_binary中调用set_brk为堆申请内存
这个函数做了两件事情
- 为数据段申请虚拟内存
- 初始化堆的指针, 这个时候因为堆还是空的, brk和start_brk是相同的值
跳转到程序入口执行
ELF文件头中记录了程序的入口地址, 如果是非动态链接加载的过程, 入口地址就是这个. 如果是动态链接, 由动态链接器先来加载运行, 然后再回调到程序的代码入口地址.
小结
可执行文件格式
在Linux中可执行文件主要是ELF(Executable and Linkable Format)格式
这个格式由
- 文件头: 记录了整个文件的一些编译的信息, 以及程序的入口地址, Program Header Table以及Section Header Table的大小及开始位置
- Section: ELF文件中最基础的单位, 我们的代码中的各个部分最后都会在编译后被放入到某一个Section中, 其中函数会被放入到.text中, 全局变量会被放入到.data, .bss中
- Segment: 不同的Section有不同的权限(E, R, W), Linux为了能更快的加载, 将相同权限的Section放在一起组合成了一个Segment
- Program Header Table: 记录了每个Segment的类型, 偏移量, 大小, 权限等信息
- Section Header Table: 记录了每个Section的类型, 偏移量, 大小, 权限等信息
shell是怎么将程序执行起来的
Linux在初始化的时候, 会将所有的支持的可执行文件的加载器都注册到一个全局链表中, 对于ELF, 它的加载器在内核中定义为elf_format, 它加载二进制文件的入口是load_elf_binary函数
shell进程一般是通过fork + execve的形式来加载并运行新的进程的. 执行fork系统调用会创建出来一个新进程, 不过新的进程和原来的进程几乎一摸一样, 在这个基础上, 我们想让新的进程运行我们ELF文件, 就需要execve系统调用
通过execve系统调用, 我们首先会进入到do_execve函数中, 然后进入到核心函数do_execve_common
alloc_brpm申请并初始化bprm内核临时对象, 这个对象是加载ELF文件的时候的临时数据结构- 这一步会为bprm内核对象分配物理内存, 然后创建mm_struct, 并创建一个4KB的VMA用作进程栈
bprm_execve进入到search_binary_handler, 先通过文件头判断文件的格式, 然后寻找合适的加载器, 并加载文件, 这里我们就进入到了加载器的load_binary函数中了, 对于elf文件, 就进入到了load_elf_binary函数
接下来就是加载ELF文件的过程, 基本就是解析并保存ELF文件中的每个部分的过程
- 读取文件头, 这里获取到程序的入口, Program Header, Section Header的位置, 同时会进行文件的合法性检查, 如果不合法直接退出, 会创建内核对象将解析的结果保存起来
- 然后就是读取Program Header, 并加载到物理内存中
- 然后清空父进程继承来的资源, 并将bprm中的mm和栈VMA设置到新的进程上
- 执行Segment加载, 将LOAD类型的Segment建立内存mmap, 将磁盘上的程序文件中映射到虚拟内存空间中, 这里会计算mm_struct中data等段指针的位置, 并设置到mm_struct上, 这里还会为代码段申请VMA
- 接下来调用
set_brk为数据段申请虚拟内存VMA, 并且初始化brk和start_brk这两个堆区的指针(这个时候是相等的, 因为堆还是空的) - 最后就是跳转到文件头中的程序的入口地址, 执行程序了