操作系统内存管理 - Linux物理内存篇
Linux物理内存
物理内存检测
在物理内存这个硬件和操作系统之间, 还存在着一个固件层(firmware)也叫BIOS. 它负责硬件自检, 初始化所有硬件设备, 加载操作系统引导程序, 将控制权移交给操作系统并提供结构供操作系统读取硬件信息. 操作系统所需的内存等硬件信息都是通过固件来获取的
在固件ACPI接口规范中定义了探测内存的物理分布规范. 内核请求中断15H , 并设置操作码为E820H, 因为操作码是E820, 所以这个机制也被称为E820
会在detect_memory_e820函数发出15号中断并处理所有结果, 把内存地址范围保存到boot_params.e820_table对象中. boot_params只是一个中间数据, 专门还有一个e820_table全局数据结构来保存内存地址范围, 在e820__memory_setup中会将boot_params.e820_table保存到e820_table中, 并打印出来. 服务器能通过mseg命令来查看到实际的物理内存地址.
memblock内存分配器的创建
在完成了E820机制检测到可用的内存地址范围以后, 调用e820__memory_setup把检测结果保存到e820_table全局数据结构中以后. 紧接着就是调用e820__memblock_setup创建memblock内存分配器, 这个分配器会进行初期物理内存的一个粗粒度的分配
memblock数据结构
memblock的实现非常简单, 就是按照检测的物理内存的地址范围是useable还是reserved分成两个对象, 分别使用memblock_region数组存起来
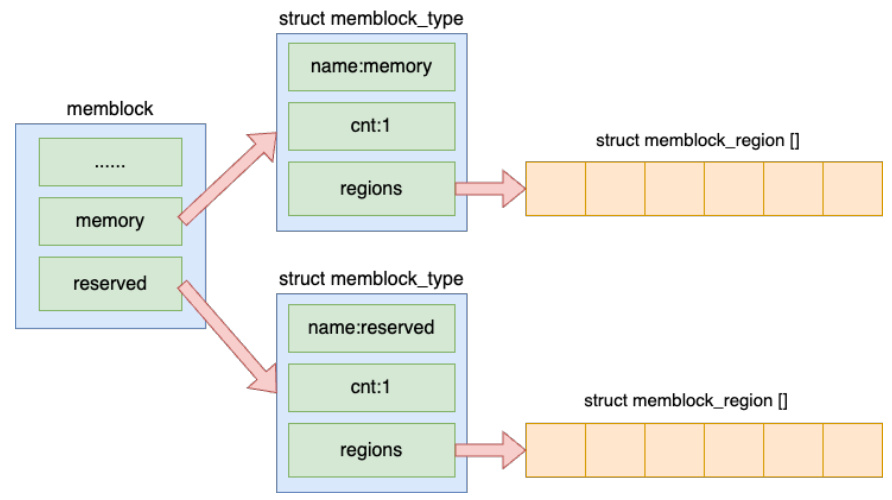
e820__memblock_setup
- 遍历e820_table中的每一段内存区域, 如果是预留内存就调用memblock_reserve添加到reserved成员中
- 如果是可用内存就调用memblock_add添加到memory成员中
- 创建完成以后还会调用依次memblock_dump_all()进行依次打印输出.不过要启用这个输出的信息需要修改Linux启动参数, 添加memblock = debug并重启才可以, 然后就能通过
dmesg来查看了
向memblock分配器申请内存
在启动时伙伴系统创建以前, 是通过memblock来分配内存的, 两个比较重要的使用场景就是crash kernel和页管理初始化
crash kernel
内核为了能在崩溃的时候记录崩溃的现场, 方便以后排查分析, 设计了一套kdump机制. 实际上是在服务器上启动了两个内核, 第一个是正常使用的内核, 第二个是崩溃发生的时候应急内核. 发生崩溃的时候kdump使用kexec启动到第二个内核中运行. 这样第一个内核中的内存就得以保留下来了. 然后就可以把崩溃时候的所有运行状态都收集到dump core中
对此机制不展开, 只是说明这个机制是需要额外的内存才能工作的
页管理初始化
Linux的伙伴系统是按页的方式来管理物理内存的, 一个页的大小是4KB. 每一个页使用一个struct page对象来表示, 这个对象也是需要消耗内存的, 这个数据结构的大小一般是64B
在内核初始化的阶段会为所有的页面都申请一个struct page对象, 将来通过这个对象对页面来进行管理.
内存页管理模型现在默认采用的是SPARSEMEM模型. 在内存中就是一个二维数组
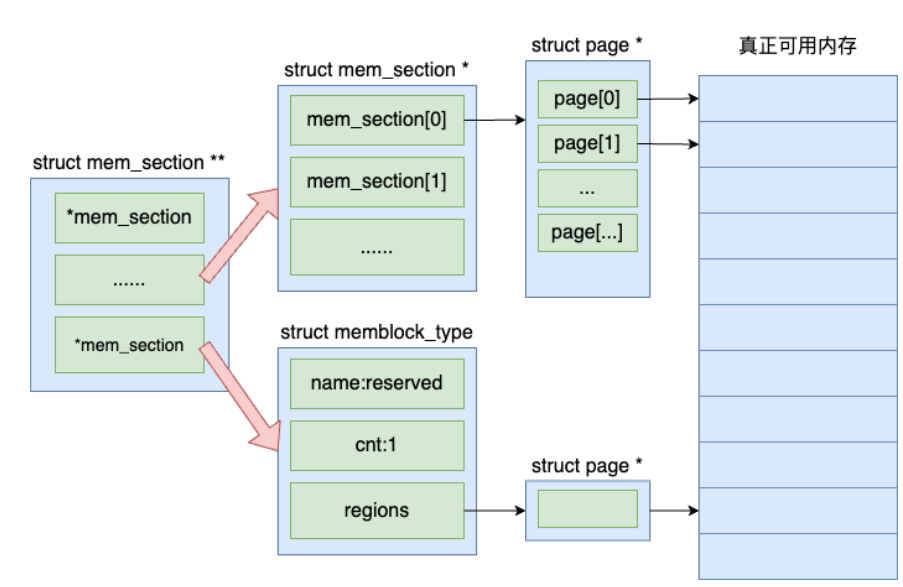
NUMA信息感知
为什么会有NUMA
NUMA : Non-Uniform Memory Access 非一致性内存访问
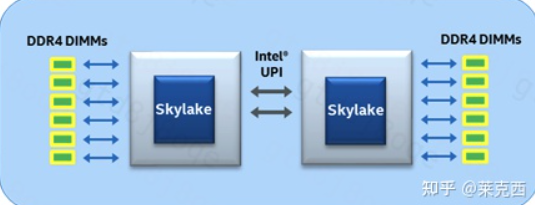
服务器主板不同于个人主机主板, 提供了CPU的拓展功能, 也就是一块主板上能有多个CPU, 每个CPU都有自己直连的内存, 如果想访问另一个CPU的直连内存, 就需要经过UPI总线.
这样的访问机制导致对于同一个CPU来说, 访问自己的直连内存与访问需要经过UPI总线的其他的CPU的直连内存, 经过的物理链路的长度是不一样的, 也就导致了访问的时延是不同的
Linux读取NUMA的信息
Linux根据内存访问特性的相似性, 将cpu核心和物理内存划分成一个个node, 比如在上面的图像中, 左边的cpu和它的直连内存就是一个node, 另一个cpu和它的直连的内存就是另一个node
在操作系统和硬件之间的fireware固件层向Linux提供了NUMA的信息, 这里主要就是向Linux提供能划分出来node的信息
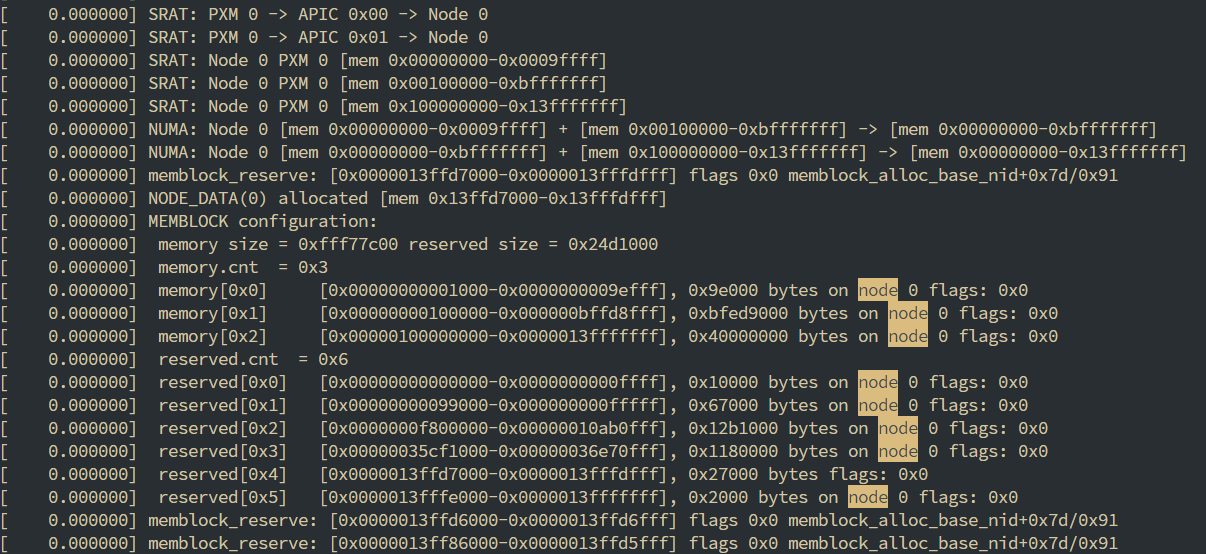
固件层向Linux操作系统提供了SRAT和SLIT两个表
- SRAT(System Resource Affinity Table): 提供了cpu核与内存的关系图, 有几个node, 每个node有几个逻辑核, 有哪些内存
- SLIT(System Locality Information Table): 提供了node之间的距离
Linux通过下图的调用链, 最终执行到x86_acpi_numa_init函数来从ACPI中读取出来SRAT表, 并将读取的结果保存在numa_meminfo这个数据结构中, 这是一个全局的列表, 每一项都是(起始地址, 结束地址, 节点编号)的三元组
1 | start_kernel |
memblock分配器关联NUMA信息
获取到内存块的node节点信息, 接下来还需要把NUMA信息写入到memblock分配器中, 来保证系统启动时的创建的数据结构能正确地分配到对应的内存节点上, 不会出现跨节点内存访问等由NUMA导致的问题, 同时在这一步让分配器感知到的NUMA信息也会被后续继承给buddy allocator
1 | start_kernel |
numa_register_memblks函数
- 将每一个memblock region和NUMA节点号关联
- 为所有可能存在的node申请pglist_data结构体空间
- 打印memblock内存分配器的详细调试信息
物理页管理之伙伴系统
memblock分配器管理的粒度太大了, 操作系统需要能申请更小的物理内存的物理内存管理系统, 这个系统就是伙伴系统(buddy allocator)
伙伴系统相关的数据结构
操作系统将物理内存划分到了一个个node中, 可以使用numactl来查看到每个node的情况
1 | # numactl --hardware |
node的信息保存在struct pglist_data node_data[]这个全局列表中
1 | struct pglist_data { |
在node下面, linux进一步划分成了三个zone, zone表示内存中的一块范围, 有三种类型
- ZONE_DMA: 地址最低的一块内存区域, 供ISA设备DMA访问(ISA设备是24位的, 这块区域对应的是16MB, 能保证向ISA设备提供的地址是24位的)
- ZONE_DMA32: 用于支持32-bits地址总线的DMA设备, 同时也可以作为普通的内存分配, 是一种向下兼容的设计
- ZONE_NORMAL: x86-64的架构下, DMA和DMA32之外的内存地址都在NORMAL的ZONE中管理
1 | # cat /proc/zoneinfo |
对于zong数据结构
1 | struct zone { |
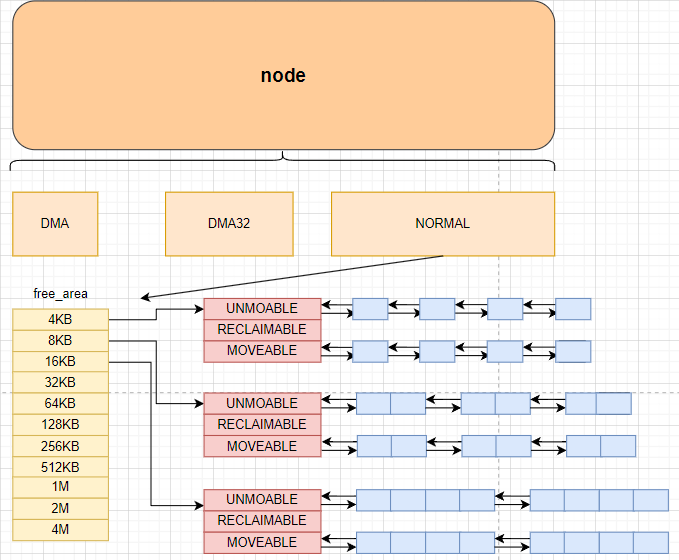
其中的free_area就是伙伴系统实现的重要的数据结构, 由此也能看出来内核中不是只有一个伙伴系统, 每一个zone都有一个伙伴系统
伙伴系统是怎么管理空闲页面的
伙伴系统中的free_area是一个有11个元素的数组, 每个数组分别代表的是空闲可分配连续4KB, 8KB, 16KB, …, 4M的内存链表
1 | # cat /proc/pagetypeinfo |
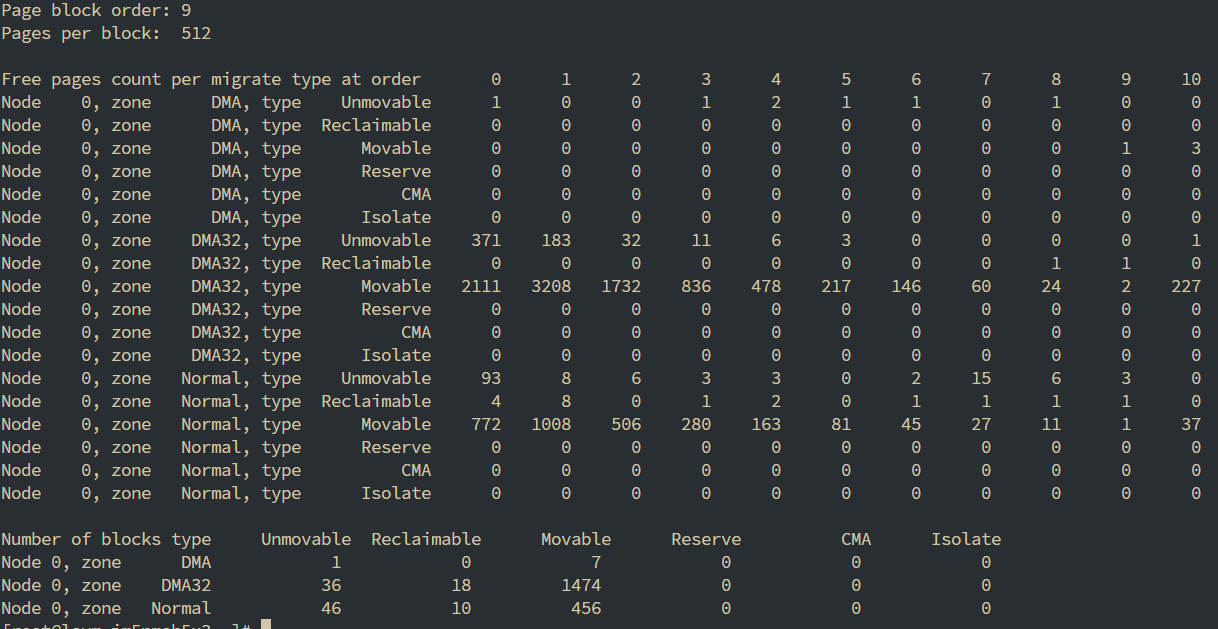
内核提供分配器函数alloc_pages到上面的链表中寻找可用连续页面
以我们要寻找8KB的物理内存为例, 忽略UNMOVABLE之类的区别, 统一按照free_list来看
- 尝试从8KB的free_list获取一块连续的8KB的内存, 获取失败, free_list中元素是null
- 向下移动一位, 尝试从16KB的free_list中获取, 获取成功, 这个时候我们将原来的16KB拆分成了两部分了, 一部分8KB是我们返回的内存
- 另一部分没使用的8KB被整理到8KB的free_list中
memblock向伙伴系统交接
交接的调度链路是
1 | start_kernel |
具体的交接过程是在memblock_free_all->free_low_memory_core_early中执行的
free_low_memory_core_early函数
- reverse内存交接
- 可用内存交接
- 通过for_each_free_mem_range遍历
- 调用
__free_memory_core释放并将页面放到zone的free_area数组中对应的位置上去
SLAB内存分配器
虽然我们已经实现了更细粒度的4KB的物理内存分配管理器, 但是很显然, 我们不可能为每个内核中的数据结构都申请一个4KB的内存页, 我们需要一种更加灵活的内存管理器. 这个需求在用户态同样是需要的, 不过用户态的程序是通过mmap/brk来申请内存, 通过ptmalloc等用户态的分配器来管理内存. 内核同样需要这样的内存分配器, 这就是SLAB内存分配器.
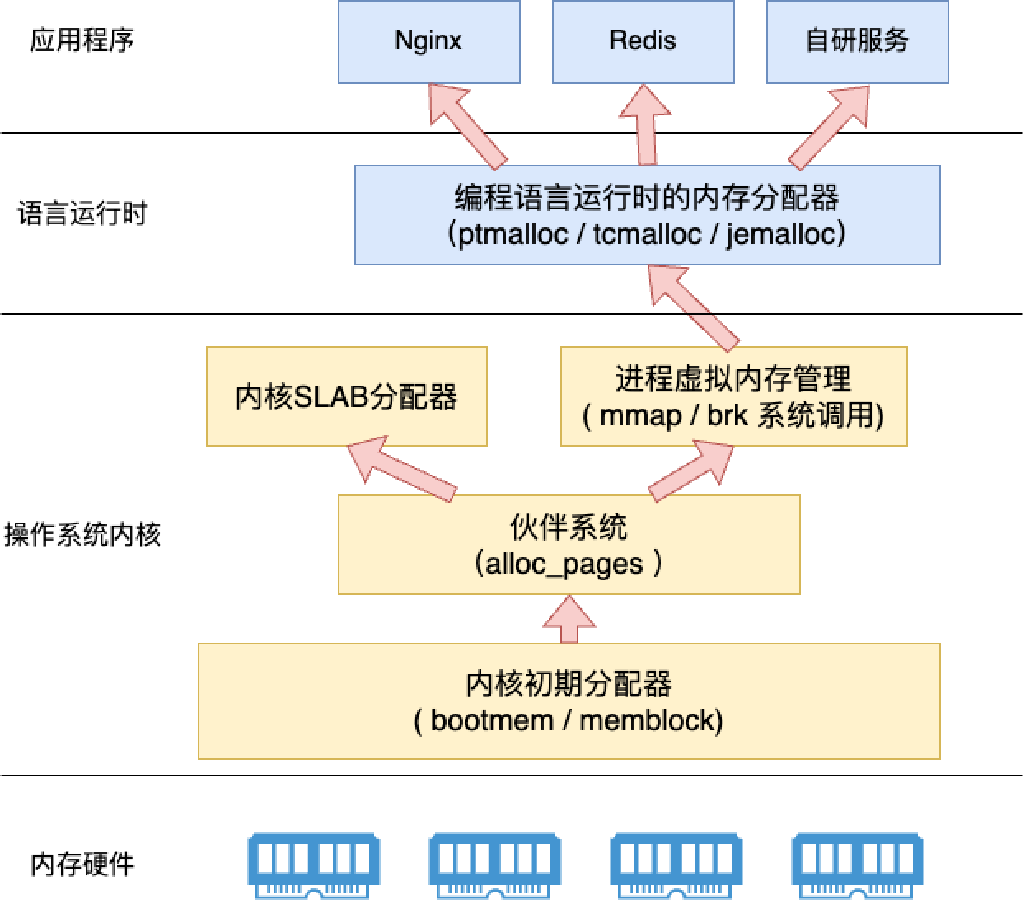
分配器原理
slab分配器抽象出来slab集装箱这个概念, 一个slab内只分配特定大小, 甚至是特定的对象. 这样当一个对象释放了内存以后, 另一个同类的对象可以直接使用这块内存
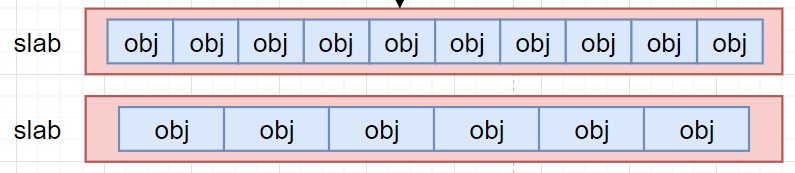
分配器实现
最基础的数据结构是kmem_cache, 这个数据结构就对应着某个特定大小或特定对象的slab池, 每个kmem_cache下又有kmem_cache_node来对应具体的内存池
1 | struct kmem_cache { |
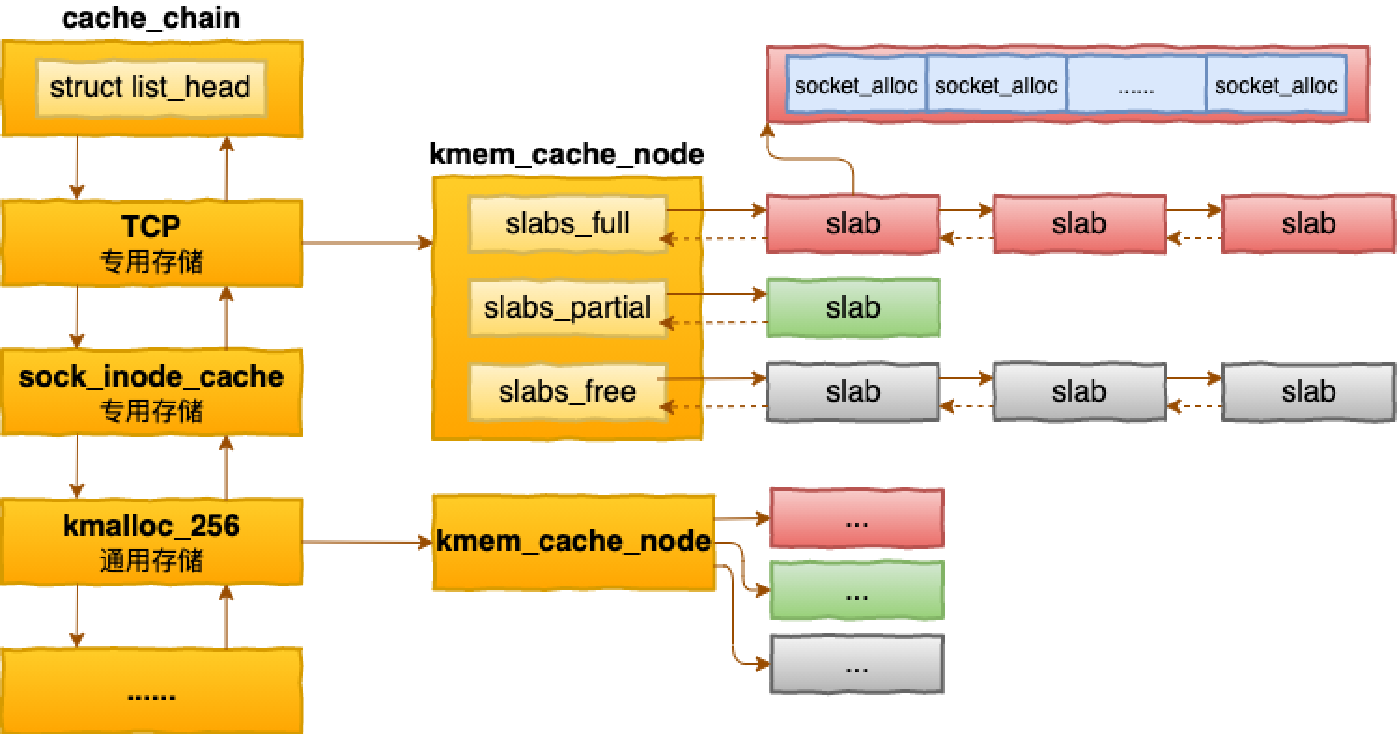
在这张图片中, 左边的cache_chain中的每一个具名实例就是一个kmem_cache的实例, 不同大小的对象都有不同的cache
分配器的接口
- kmem_cache_create: 创建一个基于slab的内核对象管理器
- kmem_cache_alloc: 快速为某个对象申请内存
- kmem_cache_free: 归还对象占用的内存给slab管理器
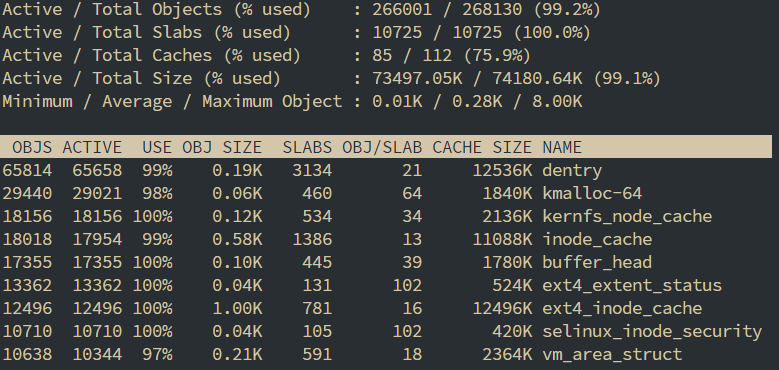
常用命令
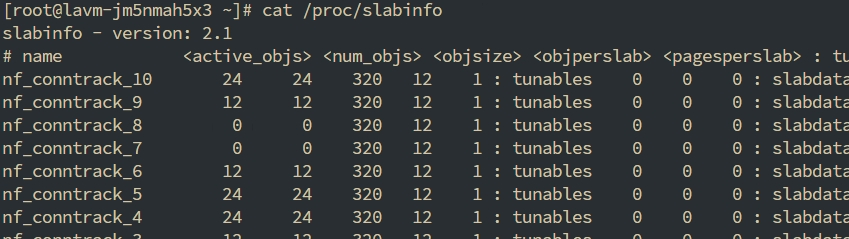
查看内核对象slabinfo, 可以看到vm_struct_area这个老熟人, active_objs有10393个, num_objs有10674个, objsize是216, objperslab是18, pagesperslab是1, 对应的含义就是, 对于这个内核对象
- 活跃的对象数量是10393
- 对象总数是10674
- 对象的大小是216 bit
- 每个slab中能存18个这个对象
- 每个slab占用1个page
1 | # cat /proc/slabinfo |
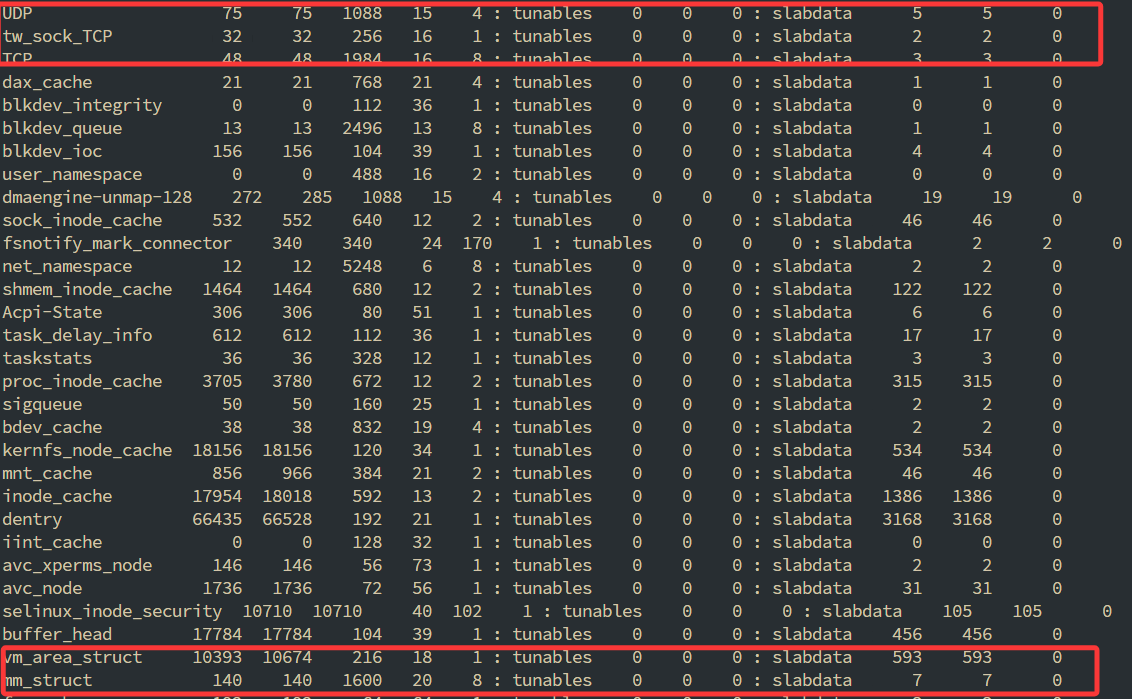
查看内核对象的内存情况
1 | # slabtop |