
操作系统内存管理 - Linux虚拟内存管理
虚拟内存管理
以问题来引入
- 申请内存申请到的真的是物理内存吗
- 对虚拟内存的申请如何转化成对物理内存的访问?
- top命令输出进程的内存指标中VIRT和RES分别是什么含义
- 堆栈的大小限制是多大, 当堆栈发生溢出以后应用程序会发生什么
- 进程栈和线程栈是一个东西吗
- malloc大概是怎么工作的
虚拟内存和物理页
为什么要有虚拟内存
- 用户进程访问内核数据要加以限制
- 用户进程之间需要隔离
- 内存不足的时候swap到硬盘上, 保证系统可正常运行
虚拟地址空间到底是什么
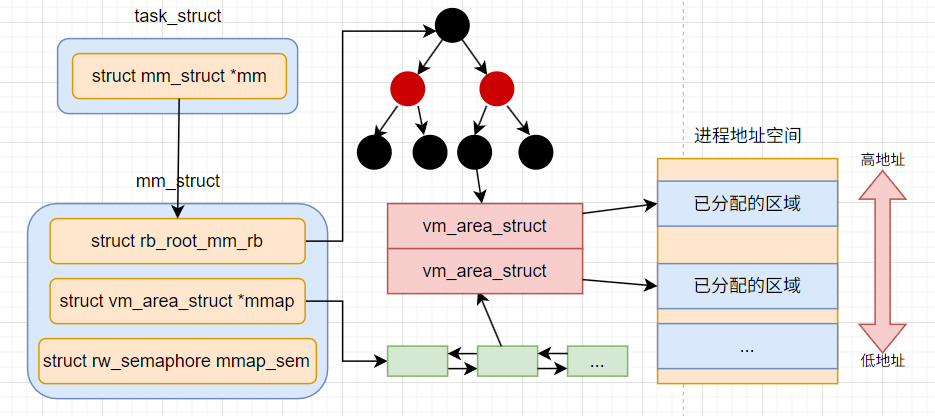
在内核中的定义, 每个进程的task_struct都有一个核心对象 - mm_struct类型的mm. 代表的就是进程的虚拟地址空间
1 | struct task_struct { |
在这个虚拟内存空间里面, 每一段已经分配出去的地址范围都是通过一个个虚拟内存区域VMA来表示, 也就是对应到内核中的数据结构vm_area_struct
1 | struct vm_area_struct { |
其中vm_start和vm_end就是使用了的虚拟地址范围的开始和结尾
通过一个个的vm_area_struct就组成了这个进程已经分配出去的地址范围, 加起来就是对整个虚拟地址空间的占用情况. 内核会保证vm_area_struct的范围之间不会有交叉的情况出现
内存访问的过程中, 需要经常查找虚拟地址和某个vm_area_strcut的对应关系. 所以我们需要合适的数据结构来组织多个vm_area_strcut
在Linux6.1之前, 使用的是红黑树来提供logn的查询效率, 双链表来提高高效遍历效率
1 | struct mm_struct{ |
这个方案最明显的缺陷就是随着现在的服务器上的核数越来越多, 多线程情况下锁争抢问题. 需要加锁的原因是红黑树的平衡操作牵扯到多个节点, 以及修改需要同步到双向链表. 所以这两个数据结构都需要加锁修改.
在Linux6.1以后, 对VMA管理换成了maple tree. 是按照RCU无锁编程方式来实现的
1 | struct mm_struct { |
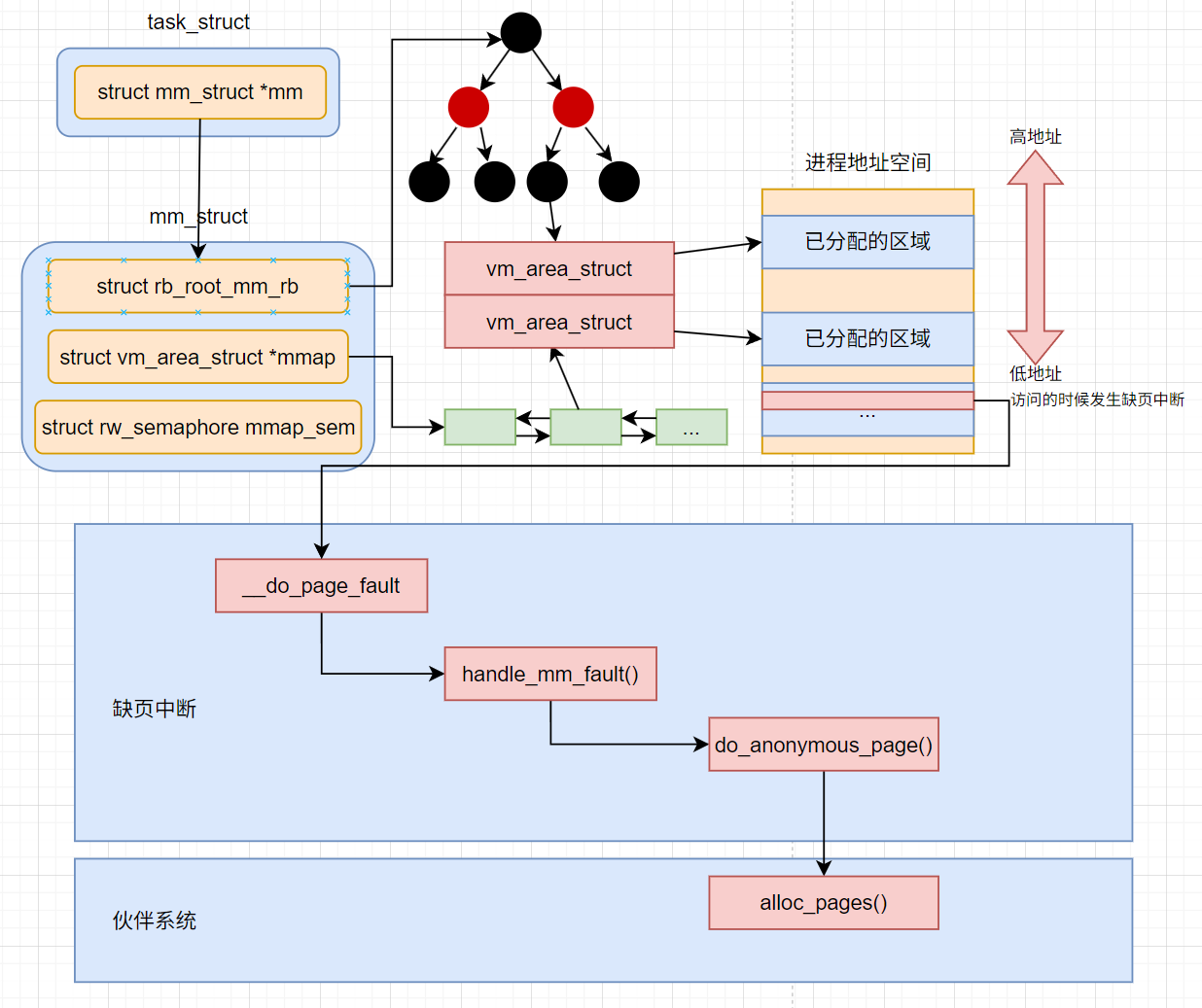
什么时候分配的物理页
这个其实是个老生常谈的话题, 也是面试常考的问题, 答案就是是在触发缺页中断的时候, 但是这里我们将深入到Linux在触发中断以后的调用的具体的函数和涉及到的具体的数据结构来看
当进程在运行的过程中, 在栈上开始分配和访问变量的时候, 如果物理页还没有分配,这个时候就会触发缺页中断. 在中断处理函数中来真正分配物理内存
内存缺页中断的核心处理入口do_user_addr_fault(unsigned long address)函数
vma = find_vma(mm, address): 根据新的addr来找到对应的vmafault = handle_mm_fault(mm, vma, address, flags)调用handle_mm_fault函数来真正地分配物理内存申请
find_vma(mm, address)
这个函数会优先尝试从vmacache中获取, 这是软件层面的cache, 由进程持有, 每个进程有自己VMA缓存, 缓存的内容是最近访问VMA. 下面的两个遍历操作, 都是在缓存没有命中的时候进行的
在Linux6.1以前, 因为mm_struct中的vm_area_struct是通过红黑树和双向链表组织起来的, find_vma的实现是通过遍历VMA双向链表, 找到满足vm_start <= vma <= vm_end的VMA并返回()
在6.1及以后, 组织VMA的数据结构也变成了maple_tree, find_vma也就变成了调用maple tree的查找函数mas_walk来查询了
在find_vma找到了正确的vma以后, 就进入到了真正的物理内存的分配, 会依次调用handle_mm_fault->__handle_mm_fault来完成物理内存分配
__handle_mm_fault(vma, addr…)
首先要介绍在现在的64位的cpu下, 四级的虚拟内存页表
- 一级页表: Page Global Dir, 简称 pgd
- 二级页表: Page Upper Dir, 简称pud
- 三级页表: Page Mid Dir, 简称pmd
- 四级页表: Page Table, 简称pte
在__handle_mm_fault(vma, addr...)中
- 依次查看或申请每一级的页表项
- 完成对页表的处理以后, 在
handle_pte_fault(vm_fault)中进入到do_anoymous_page中进行处理 - 在
do_anonymous_page中调用alloc_zeroed_user_highpage_movable分配一个可移动的匿名物理页出来, 在底层会调用伙伴系统的alloc_pages进行实际物理页面的分配
handle_pte_fault(vm_fault)会处理很多种内存缺页处理, 比如文件映射缺页处理, swap缺页处理, 写时复制缺页处理, 匿名映射页缺页处理等情况. 开发者申请的变量内存对应的是匿名映射页处理, 会进入到do_anonymous_page
内核是用伙伴系统来管理所有的物理页的 其他的模块需要物理页的时候都会调用伙伴系统对外提供的函数来申请物理内存
小结
申请内存申请到的真的是物理内存吗
申请的时候实际上只会申请VMA, 真正的物理内存是等到访问的时候触发缺页中断, 再调用alloc_pages从伙伴系统中申请
进程的堆栈的物理内存分配时间也是同样的, 创建进程的时候新进程的栈内存分配的也只是一段地址空间范围
top命令输出进程的内存指标中VIRT和RES分别是什么含义
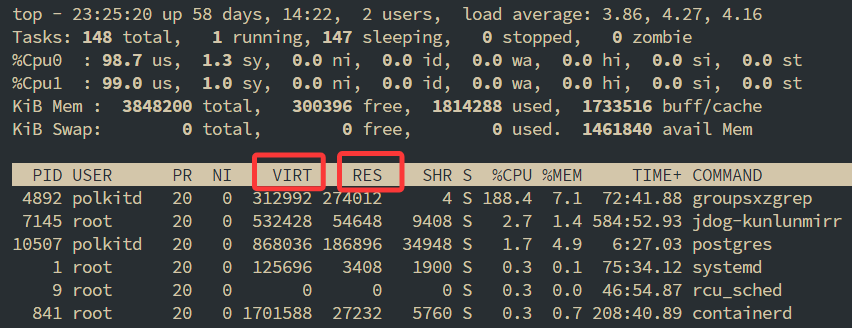
VIRT就是进程使用的虚拟内存的大小, RES就是进程实际申请的物理内存的大小
虚拟内存使用方式
整个进程的运行过程中, 几乎都是在围绕着对虚拟内存的分配和使用而进行的, 具体的使用方式主要有三种
第一类是操作系统加载程序时在加载逻辑里对新进程的虚拟内存的设置和使用
- 程序启动时, 加载程序会将程序代码段, 数据段通过mmap映射到虚拟地址空间中
- 对新进程初始化栈区和堆区
第二类是程序运行期间动态地对所存储各种数据进行申请和释放. 涉及到栈, 进程线程运行时函数调用, 存储局部变量使用到的都是栈
第三类是堆, 各种开发语言运行时通过new, malloc等函数就是从堆中分配内存. 这类内存申请和释放需要依赖操作系统提供的关系虚拟地址空间相关的mmap, brk等系统调用来实现.
进程启动时对虚拟内存的使用
在进程加载完毕以后, 在解析完ELF文件信息以后
- 为进程创建新的地址空间, 同时为其准备一个默认大小4KB的栈
- 将可执行文件以及它所依赖的各种动态链接so库通过elf_map函数映射到虚拟地址空间中
- 对堆区进行初始化
在程序加载启动成功以后, 在进程的地址空间中的代码段, 数据段设置完毕, 堆, 栈也都准备好了
底层实现上, 上面四者在底层都是对应一个个的vm_area_struct对象, 每一个vma都表示这段虚拟内存空间已经被分配和使用了
对于栈的申请
是在execve依次调用do_execve_common, bprm_mm_init, 最后在__bprm_mm_init中申请的vma对象
对于可执行文件以及进程所依赖的各种so动态链接库
execve时依次调用do_execve_common, search_binary_handler, load_elf_binary, elf_map, 调用mmap_region申请vm_area_struct对象, 最终将可执行文件中的代码段, 数据段等映射到内存中
对于堆内存
在load_elf_binary的最后set_brk初始化堆的时候, 依次调用vm_brk_flags, 最后成功申请vma对象
可以使用cat/proc/<pid>/maps来查看进程的虚拟地址空间概要
mmap
这个系统调用是虚拟内存管理中提供的最接近底层调用, 也是最常用的mmap. 可以用于文件映射和匿名映射, 这里我们忽略文件映射.
匿名映射这个名字有一些的迷惑性, 实际上是文件映射有文件, 而匿名映射没有对应的物理文件, 直接叫普通内存地址空间会更容易理解
匿名映射的过程实际上就是向内核申请一段可用的内存地址范围而已, 非常简单. 也就是调用了mmap以后, 内核就会多申请一个vm_area_struct出来. 表示这段内存可用, 然后返回给用户.
mmap的调用逻辑比较深, mmap => ksts_mmap_pgoff => vm_mmap_pgoff => do_mmap_pgoff => do_mmap => mmap_region. 最关键的就是最后的mmap_region
在这个位置会申请新的vm_area_struct, 并对其初始化(初始化vm_start和vm_end), 最后返回addr, 也就是虚拟地址的起始位置
这个时候用户申请的虚拟空间就申请好了, 用户就可以使用了.
sbrk/brk
在set_brk中会先为数据段申请虚拟内存, 然后初始化堆区的指针, mm_struct->brk = end(这里的end是数据段的末尾)
从set_brk开始, 依次调用到do_brk_flags的时候申请堆区内存(也就是申请了vma), 然后初始化mm中和堆区相关的值, brk指向的就是堆区的终止地址, start_brk指向堆区的起始地址(也就是数据段的末尾)
- sbrk系统调用: 返回mm_struct->brk的指针值
- brk系统调用: 修改mm_struct->brk的指针值
- 往大了改就是加大堆区
- 往小了改就是缩小堆区
进程栈内存的使用
从问题开始
- 进程栈的大小限制是多少
- 栈限制的大小可以调整吗, 可以的话怎么调整
- 栈溢出以后会发生什么
进程栈的初始化
加载系统调用execve依次调用do_execve_common,
- 在
bprm_mm_init的时候申请一个全新的地址空间mm_struct对象, 准备给新的进程使用. - 申请完地址空间以后, 调用
__bprm_mm_init为新进程的栈申请一页大小的虚拟内存空间, 作为给新进程准备的栈内存. 申请完以后, 把栈的指针(vma->vm_end - sizeof(void *))保存到bprm->p中记录起来
1 | bprm->vma = vma = vm_area_alloc(mm); |
接下来进程加载过程会使用load_elf_binary真正开始加载可执行二进制程序. 在加载时把前面的进程栈的地址空间指针设置到新进程mm对象上
1 | current->mm->start_stack = bprm->p; |
这个时候, 新的进程就能使用进程栈内存了
栈的自动增长
随着进程的运行, 进程的栈空间超过4KB是难免的问题, 这个时候进程的栈空间就需要增长
首先会进入到缺页处理函数里面__do_page_fault, 然后会进入到处理用户进程的缺页异常处理函数do_user_addr_fault
do_user_addr_fault
1 | // arch/x86/mm/fault.c |
__do_page_fault实际上是之前版本的缺页处理函数, 在6.1已经更名为handle_page_fault, 这里为了和前面以及市面上广泛的教材保持一致, 使用前者
栈一般是向下的增长的, 如果vma->start > addr表示栈不够用了, 这个时候就需要调用expand_stack进行扩张
其实在Linux栈地址空间增长是分成两种的, 一种是从高地址往低地址增长, 一种是反过来. 大部分情况都是由高往低增长. 这里只以向下增长为例
1 | // mm/mmap.c |
这个函数进行了两个运算
- 计算出来扩张以后栈的大小.
size = vma->vm_end - address; - 计算需要扩张以后的页面数量.
grow = (vma->vm_start - address) >> PAGE_SHIFT;
扩充的操作就是简单粗暴的修改vm_start就行
接下来看到acct_stack_growth进行了哪些限制判断
1 | // mm/mmap.c |
acct_stack_growth主要进行了两个判断
- may_expand_vm判断的是增长完这几个页以后, 是否超出整体虚拟地址空间大小的限制
- rlimit判断是否超出栈的大小限制
后者栈的大小限制, 能通过命令查看
1 | # ulimit -a |
也能通过命令来修改
- 重启后会丢失
1 | ulimit -s <new_size> |
- 重启后不会丢失
1 | vim /etc/security/limits.conf |
线程栈是怎么使用内存的
在Linux内核里面其实并没有线程这个概念, 内核原生的clone系统调用只是支持生成一个和父进程共享地址空间等资源的轻量级进程而已
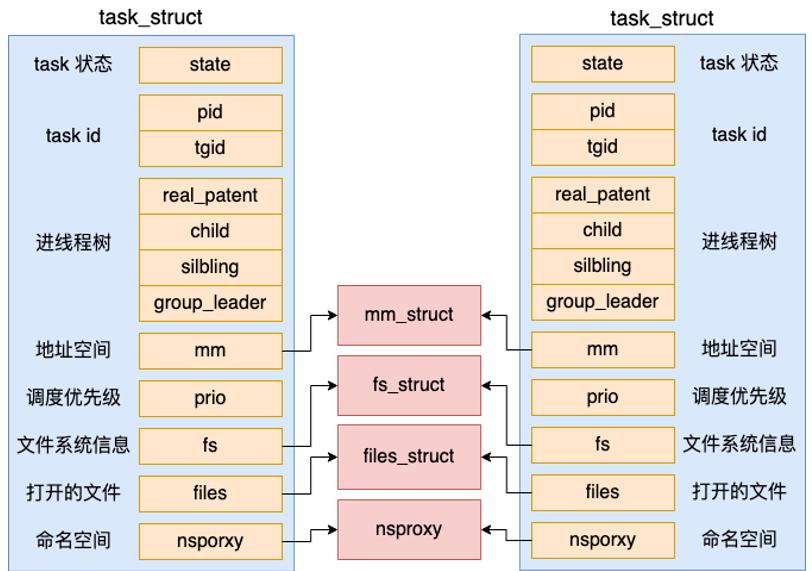
Linux的线程包含了两部分的实现
- 第一部分是用户态的glibc库, 创建线程的时候调用的pthread_create就是在glibc实现的, glibc完全是用户态运行的, 不是内核源码
- 内核态的clone系统调用, 内核通过clone系统调用可以创建出来和父进程共享地址空间的轻量级用户进程
glibc的线程对象
线程包括了内核态和用户态的两部分的实现, 所对应的资源也是同样的分成了两部分, 一部分是内核资源, 例如代表轻量级进程的内核对象task_struct, 另一部分就是用户态的资源, 包含线程栈. 在C语言glibc中的实现中, 用户资源这一部分的核心的数据结构就是pthread. 存储了线程的相关信息, 包含了线程栈
1 | // file:nptl/descr.h |
- tid对象存储了线程的ID值
- stackblock指向了线程栈内存
- stackblock_size表明栈的内存区域大小
线程栈的创建
pthread_create的调用路径是__pthread_create_2_1 -> create_thread
create_thread
- 定义线程对象 pthread
- 执行
ALLOCATE_STACK- 确定栈空间的大小
- 申请用户栈内存
- 创建用户进程
ALLOCATE_STACK是一个宏, 最后会调用到allocate_stack函数
allocate_stack
- 确定栈空间大小:
size = attr->stacksize ?: __default_stacksize;如果用户创建线程的时候指定了栈的大小, 就会使用用户指定的大小, 如果没有指定, 就会使用默认的大小
在
__pthread_initialize_minimal_internal中会为__default_stacksize这个变量赋值, 逻辑是
- 如果ulimit没有配置或者配置的是无限大, 那么大小就是ARCH_STACK_DEFAULT_SIZE (32
MB)- 如果用户配置的太小了, 可能会导致程序无法正常运行, glibc也给了一个PTHREAD_STACK_MIN (16384B)
- 在ulimit配置合理的情况下, 会将配置数值对齐一下就会使用了
- 确定完栈空间大小以后, 就要执行栈空间的申请了
- 首先尝试通过
get_cached_stack获取一块缓存直接用 - 假设没有取到缓存, 就使用
mmap系统调用直接申请一块匿名页内存空间 - 将pthread对象放到栈上
- 将栈添加到全局在用栈的链表中管理起来
- 首先尝试通过
通过这里的我们能发现, 线程栈是不能伸缩的, 并没有想进程栈一样, 提供了伸缩的函数, 和判断进程栈是不是用超了的逻辑, 所以线程栈要是用超了, 就要开始报错了
在栈申请好以后, 在create_thread中调用do_clone系统调用开始创建
glibc中的每个线程在结束阶段都会执行一个公共操作, 释放掉那些已结束线程的栈空间, 从stack_used移除, 放入到stack_cache中, 相当于析构函数
小结
进程栈和线程栈式一个东西吗
进程栈
- 持有的资源是完完全全的内核态的资源,
- 在创建进程的时候完成初始化,
- 默认是4KB,
- 在访问栈内存的时候会执行expand_stack自动扩容, 有向下和向上两种扩容逻辑
而Linux中glibc中的线程库是nptl线程, 包含了两部分的资源
- 第一部分是内核态中的task_struct, 地址空间等内核对象.
- 另一部分就是用户态的管理用户的线程对象的pthread,
- 申请的栈内存最大32MB, 最小16384B, 可以在创建线程的时候指定大小,
- 不能动态伸缩
- 同时维护了全局链表stack_used和stack_cache, 结束的线程会做将栈内存从stack_used中移除, 添加到stack_cache中, 创建线程的时候会优先尝试从stack_cache中获取
进程的栈默认是进程使用的, 线程是不能使用进程的栈的, 所以才需要额外的线程的的栈内存
glibc中的每个线程在结束阶段都会执行一个公共操作, 释放掉那些已结束线程的栈空间, 从stack_used移除, 放入到stack_cache中, 相当于析构函数
堆栈的大小限制是多大, 当堆栈发生溢出以后应用程序会发生什么
进程的栈, 默认是4KB, 线程栈最小是16438B, 最大不超过32MB, 默认是ulimit -a中的栈的配置的大小, 栈溢出以后因为访问了没有申请的内存, 会发生Segmentation fault
进程栈的大小限制是多少
进程栈最大大小通过ulimit -a中的stack size来限制
栈限制的大小可以调整吗, 可以的话怎么调整
通过 ulimit -s <size>和修改 /etc/security/limits.conf文件来调整
malloc堆内存分配原理
如果只是使用裸的系统调用来使用和分配内存, 很容易出现的问题就是内部和外部的内存碎片, 同时每次申请内存都需要进入到内核态执行系统调用, 开销很大
所以我们需要一个任意大小内存块管理的机制. 内存管理器的核心机制都是类似的. 都是预先向操作系统申请一些内存
- 当我们申请内存的时候, 直接由分配器从预先申请好的内存池里申请
- 释放内存的时候, 分配器会将这些内存管理起来, 通过一些策略来判断是否要将其回收给操作系统
malloc_chunk: 最小内存分配单位
1 | // file:malloc/malloc.c |
上面的内容字段实际上是malloc_chunk的header部分, 实际申请的内存是紧接着header的后面的. 这种机制使malloc_chunk非常的灵活.

ptmalloc: 内存分配器
每次调用malloc申请内存的时候, 分配器都会给我们分配一个chunk出来, 并把body部分的user data地址返回给用户程序
chunk如果还没有分配出去, 或者通过free释放的话. 内存实际上并不会归还给内核. 而是glibc又组织起来
Arena
ptmalloc的第一个单元其实并不是malloc_chunk而是malloc_state, 可以简单的将一个malloc_state看作是一个内存池
1 | // file:malloc/malloc.c |
最开始的版本的malloc是使用全局锁来保证多线程竞争情况下的安全性, 但是一个全局锁导致竞争严重, 无法有效利用多核CPU, 于是分配器抽象出来了一个Arena的概念, 一个Arena就相当一个内存池, 只有使用同一个Arena的线程之间要竞争锁.
什么时候创建Arena?
在程序启动的时候会创建一个main_arena.
1 | //file: malloc/malloc.c |
在后续多线程调用malloc的时候
- 尝试get空闲的arena, 如果没有尝试创建
- 同时没有空闲的arena, 创建失败, 或者因为arena数量已经达到上限了, 无法创建arena, 这个时候才会出现多个线程之间复用一个arena然后出现malloc的锁竞争问题
分配区下管理内存的数据结构
1 | struct malloc_state |
这里剩下的就是和管理内存的相关的最核心的数据结构
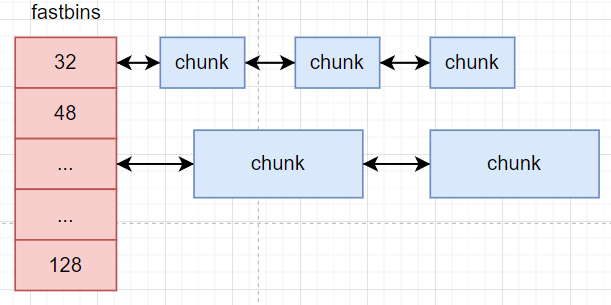
glibc会将相似大小的空闲chunk都串起来, 这样下次用户再来分配的时候, 找到链表就可以快速分配. 这样的一个链表被称为一个bin
fastbins: 用于管理小块的内存, 用来支持小内存的快速申请
unsorted bins, small bins, large bins
unsorted bins
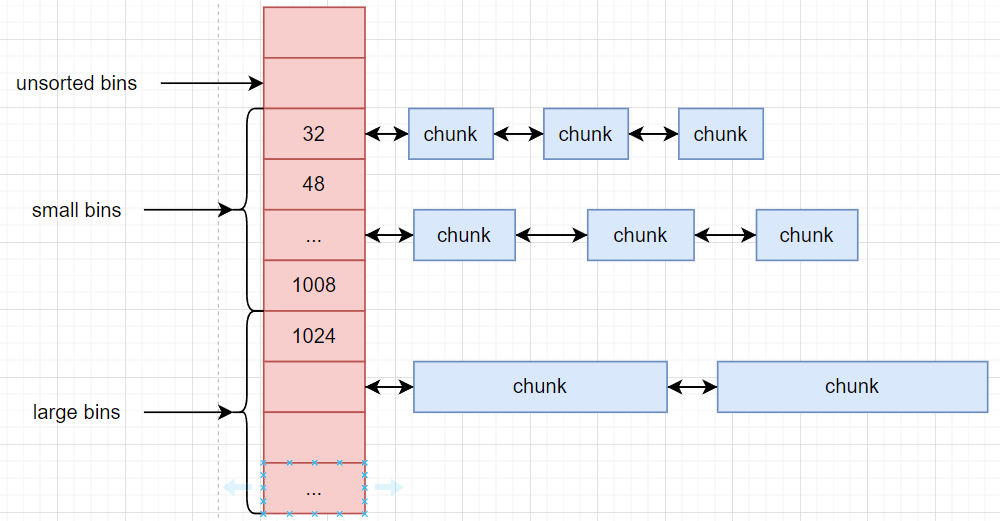
在将内存free的时候, 并不会直接将chunk放到对应的bin上, 而是会先统一地放到unsorted bins上, unsorted bins相当于bins的缓冲区
small bins, large bins
分别管理32~1008B的chunk和大于1024B的chunk
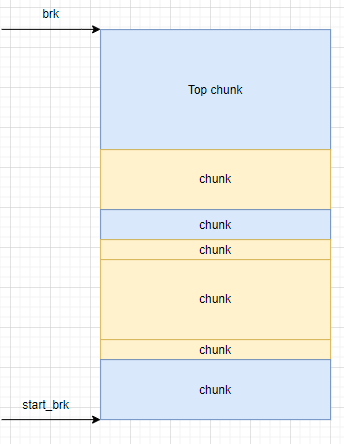
从地址空间的视角来看, 堆中的内存基本上是由一个又一个chunk组成的, 其中有个特殊的chunk是Top chunk, 它是所有没有申请了的但是没有被分配的内存的集合
malloc的工作过程
申请内存步骤
- 对用户请求的内存规范化, 对齐到32, 48, 64等字节数
- fast bin 申请: 如果申请的字节数小于fastbin管理的内存块的最大字节数, 则尝试从fastbin中获取, 申请成功则返回. 用于快速处理频繁的小内存管理
- small bin 申请: 尝试从small bins中申请内存, 申请成功返回, 处理32 - 1008之间大小的内存块的申请
- unsorted bin 申请: 尝试从unsorted bins中申请内存, 成功则返回. 这里是为了首先将free时回收的内存利用起来, 顺带地会把chunk往small large里面整理
- unsorted bin 申请: 尝试从unsorted bins中申请内存, 成功则返回. 这里是为了处理1024以上的大内存块的申请
- top chunk 申请: 前面的申请都没有成功,尝试从top chunk中申请
- 从操作系统中申请: 最后的兜底解决方法就是向操作系统中申请