
分布式架构-远程服务调用 (RPC)
远程服务调用 (RPC)
参考: 主要是基于凤凰架构改动, 推荐阅读原文
进程间通信
RPC最初出现的时候, 是希望能提供一种像调用本地方法一样调用远程方法的技术, 虽然现在已经不是这样了, 但至少它的初心是这样的
我们是怎么调用一个本地方法的?
1 | // Caller : 方法的调用者, 也就是程序中的main函数 |
完成这样的以一个方法的整体的流程是
- 传递方法参数: 将方法的参数入栈,将
hello world的引用地址入栈 - 确定方法的版本: 根据
println()的方法签名, 确定其执行的版本 - 执行被回调的方法: 从栈中弹出
Parameter的值或者引用, 以此为输入, 执行方法中的逻辑 - 返回执行结果: 将执行的结果压栈, 并将程序的指令流恢复到
Call Site的下一条指令
如果要执行的方法不在当前进程的地址空间, 我们至少要面临两个直接问题
- 传递方法参数和返回执行结果都直接依赖于本地内存中的栈, 如果是远程方法, 我们该怎么传递参数和返回执行结果
- 方法版本的选择依赖于语言规则的定义, 如果
Caller和Callee是不同的语言来实现的, 方法版本的选择就会使一项模糊的不可知行为
我们先看到第一问题, 我们怎么解决两个进程之间的通信问题, 这个问题在计算机科学中被称为 “进程间通信 (Inter-Process Communication, IPC)“, 常见的解决方式有
- 管道(Pipe)或者具名管道(Named Pipe): 可以通过管道在两个进程之间传递少量的字符流或者字节流. 普通管道只能用于有亲缘关系的进程, 而具名管道允许无亲缘关系进程间的通信
- 信号(Sinal): 通知目标进程有某件事发生, 典型应用就是
kill命令kill -9 pid的语义就是向pid是pid的进程发送编号是9的信号 - 信号量(Semaphore): 信号量用于多个进程之间同步协作
- 消息队列 (Message Queue): 上面的三种方式都只适用于传递较少的信息, 如果进程间要传递的数据量较多的时候, 使用消息队列. 进程可以向消息队列中添加消息, 赋予读权限的进程可以从消息队列中消费消息
- 共享内存 (Shared Memory): 古老而最高效的通信方式, 允许多个进程访问同一块公共的内存空间. 可以通过让进程主动创建, 映射, 分离, 控制某一块内存的程序接口
- 套接字接口 (Socket) : 上面的方式都只适用于单机进程间通信, 而Socket是更普适的进程间通信的手段, 可以用于不同机器间的进程通信. 在仅限于本机通信的时候, Socket有效率上的优化, 不再会经过协议栈, 而是简单地将应用层的数据从一个进程拷贝到另一个进程, 这种进程间通信的方式被称为: UNIX Domain Socket, 又叫做 IPC Socket
IPC和RPC之间关系
在介绍Socket这种通信方式的时候, 我们似乎发现了能让我们实现程序员透明地调用远程服务的方法, Socket是多系统支持的通用的基于网络的进程间通信的手段, 我们只要将远程方法的调用的通信细节隐藏在操作系统底层, 从应用层面上来看就能做到远程服务调用和本地的进程间通信在编码上完全一致.
但是这种透明的调用形式反而造成了程序员误以为通信是无成本的假象, 因此被滥用导致分布式系统的性能显著降低
最终这种模式也因为这种滥用现象被抛弃了
1994 年至 1997 年间,由 ACM 和 Sun 院士Peter Deutsch、套接字接口发明者Bill Joy、Java 之父James Gosling等一众在 Sun Microsystems 工作的大佬们共同总结了通过网络进行分布式运算的八宗罪(8 Fallacies of Distributed Computing):
- The network is reliable —— 网络是可靠的。
- Latency is zero —— 延迟是不存在的。
- Bandwidth is infinite —— 带宽是无限的。
- The network is secure —— 网络是安全的。
- Topology doesn’t change —— 拓扑结构是一成不变的。
- There is one administrator —— 总会有一个管理员。
- Transport cost is zero —— 不必考虑传输成本。
- The network is homogeneous —— 网络是同质化的。
上面的八条反话解释了远程服务调用如果要弄透明化, 就必须为这些罪过买单. 至此RPC是否能等同于IPC来实现暂时下了一个定论 : RPC应该是一种高层次或者说是语言层面的特征, 而不是像IPC一样是低层次或者说系统层次的特征成为了工业界和学术界的主流观点
额外知识:首次提出远程服务调用的定义
Remote procedure call is the synchronous language-level transfer of control between programs in disjoint address spaces whose primary communication medium is a narrow channel.
远程服务调用是指位于互不重合的内存地址空间中的两个程序,在语言层面上,以同步的方式使用带宽有限的信道来传输程序控制信息。
—— Bruce Jay Nelson,Remote Procedure Call,Xerox PARC,1981
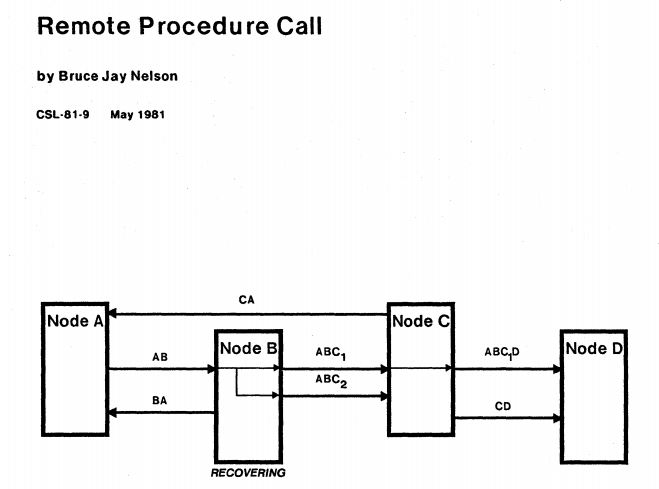
三个基本的问题
RPC协议要解决的三个基本的问题
- 如何表示数据: 因为在远程服务调用中, 我们如果想传递返回结果或者是参数, 不可避免的问题是
Caller和Callee使用的语言可能不一样, 即使语言是统一的, 也面临着操作系统, 硬件指令层面上的细节上的差异. 我们需要一个中间转义层, 也就是序列化协议. 常见的有:- ONC RPC 的External Data Representation (XDR)
- CORBA 的Common Data Representation(CDR)
- Java RMI 的Java Object Serialization Stream Protocol
- gRPC 的Protocol Buffers
- Web Service 的XML Serialization
- 众多轻量级 RPC 支持的JSON Serialization
- …
- 怎么传递数据: 怎么通过网络在两个服务之间的Endpoint之间互相操作交换数据. 这里的交换数据通常指的是应用层协议. 两个服务交互不是只扔个序列化数据流来表示参数和结果就行的,许多在此之外信息,譬如异常、超时、安全、认证、授权、事务,等等,都可能产生双方需要交换信息的需求。在计算机科学中,专门有一个名称“Wire Protocol”来用于表示这种两个 Endpoint 之间交换这类数据的行为,常见的 Wire Protocol 有:
- Java RMI 的Java Remote Message Protocol(JRMP,也支持RMI-IIOP)
- CORBA 的Internet Inter ORB Protocol(IIOP,是 GIOP 协议在 IP 协议上的实现版本)
- DDS 的Real Time Publish Subscribe Protocol(RTPS)
- Web Service 的Simple Object Access Protocol(SOAP)
- 如果要求足够简单,双方都是 HTTP Endpoint,直接使用 HTTP 协议也是可以的(如 JSON-RPC)
- …
- 如何确定方法: 在远程调用方法的时候因为Caller和Calle语言上的差异, 每门语言的方法签名都可能有所差异, “如何表示同一个方法”和”如何找到对应的方法成了问题”. 最开始想的是直接通过UUID来给方法编号, 调用的时候直接调用编号就行了, 不过最终DCE还是弄出来了一个语言无关的接口描述语言 (Interface Description Language, IDL)
- Android 的Android Interface Definition Language(AIDL)
- CORBA 的OMG Interface Definition Language(OMG IDL)
- Web Service 的Web Service Description Language(WSDL)
- JSON-RPC 的JSON Web Service Protocol(JSON-WSP)
统一与分裂的RPC
最初人们都想设计出来一种统一的RPC的解决方式, 在迭代过程中从CORBA到Web Service. 但是最终是失败的. 那些面向透明, 简单的RPC协议 DCE/RPC、DCOM、Java RMI, 要么依赖于操作系统, 要么依赖于特定的语言, 总有先天的约束; 面向通用的, 普适的RPC协议; 如CORBA就无法逃过复杂性的困扰, 意图通过技术手段来屏蔽复杂性的RPC协议, 如Web Service, 又不免受到性能问题的束缚. 简单, 普适, 高性能似乎不可能同时满足.
因为一直没有同时满足上面三个特性的”完美的RPC协议”出现, 所以远程服务调用这个领域里面开始分化. 继出现过 RMI(Sun/Oracle)、Thrift(Facebook/Apache)、Dubbo(阿里巴巴/Apache)、gRPC(Google)、Motan1/2(新浪)、Finagle(Twitter)、brpc(百度/Apache)、.NET Remoting(微软)、Arvo(Hadoop)、JSON-RPC 2.0(公开规范,JSON-RPC 工作组)……等等难以穷举的协议和框架。这些 RPC 功能、特点不尽相同,有的是某种语言私有,有的能支持跨越多门语言,有的运行在应用层 HTTP 协议之上,有的能直接运行于传输层 TCP/UDP 协议之上,但肯定不存在哪一款是“最完美的 RPC”。今时今日,任何一款具有生命力的 RPC 框架,都不再去追求大而全的“完美”,而是有自己的针对性特点作为主要的发展方向,举例分析如下。
- 朝面向对象发展: 不满足于 RPC 将面向过程的编码方式带到分布式,希望在分布式系统中也能够进行跨进程的面向对象编程,代表为 RMI、.NET Remoting,之前的 CORBA 和 DCOM 也可以归入这类,这条线有一个别名叫做分布式对象(Distributed Object)。
- 朝着性能发展: 代表为 gRPC 和 Thrift. 决定RPC性能的主要因素就两个因素: 序列化效率和信息的密度. 对于序列化效率, 序列化的输出结果容量越小, 速度越快, 效率越高; 信息密度取决于协议中有效荷载所占总传输数据的比例大小, 使用的传输协议的层次越高, 信息密度就越低, XML就是前车之鉴. gRPC 是基于 HTTP/2 的,支持多路复用和 Header 压缩,Thrift 则直接基于传输层的 TCP 协议来实现,省去了额外应用层协议的开销.
- 朝着简化发展: 代表是JSON-RPC, 说要选功能最强、速度最快的 RPC 可能会很有争议,但选功能弱的、速度慢的,JSON-RPC 肯定会候选人中之一。牺牲了功能和效率,换来的是协议的简单轻便,接口与格式都更为通用,尤其适合用于 Web 浏览器这类一般不会有额外协议支持、额外客户端支持的应用场合。
经历了 RPC 框架的战国时代,开发者们终于认可了不同的 RPC 框架所提供的特性或多或少是有矛盾的,很难有某一种框架说“我全部都要”。要把面向对象那套全搬过来,就注定不会太简单,如建 Stub、Skeleton 就很烦了,即使由 IDL 生成也很麻烦;功能多起来,协议就要弄得复杂,效率一般就会受影响;要简单易用,那很多事情就必须遵循约定而不是配置才行;要重视效率,那就需要采用二进制的序列化器和较底层的传输协议,支持的语言范围容易受限。也正是每一种 RPC 框架都有不完美的地方,所以才导致不断有新的 RPC 轮子出现,决定了选择框架时在获得一些利益的同时,要付出另外一些代价。
最近几年, RPC框架有明显的朝着更高层次 (不仅仅负责调用远程服务, 还管理远程服务) 与插件化方向发展的趋势, 不再独立追求解决RPC的全部三个问题 (表示数据,传递数据, 表示方法, 追求提供核心的, 更高层次的能力, 譬如提供负载均衡, 服务注册, 可观察性等方面的支持. 这一类框架的代表有 Facebook 的 Thrift 与阿里的 Dubbo。尤其是断更多年后重启的 Dubbo 表现得更为明显,它默认有自己的传输协议(Dubbo 协议),同时也支持其他协议;默认采用 Hessian 2 作为序列化器,如果你有 JSON 的需求,可以替换为 Fastjson,如果你对性能有更高的追求,可以替换为Kryo、FST、Protocol Buffers 等效率更好的序列化器,如果你不想依赖其他组件库,直接使用 JDK 自带的序列化器也是可以的。这种设计在一定程度上缓和了 RPC 框架必须取舍,难以完美的缺憾。