
操作系统I/O - 零拷贝
I/O的演进
DMA技术
在最开始的时候, 读一个文件的过程是
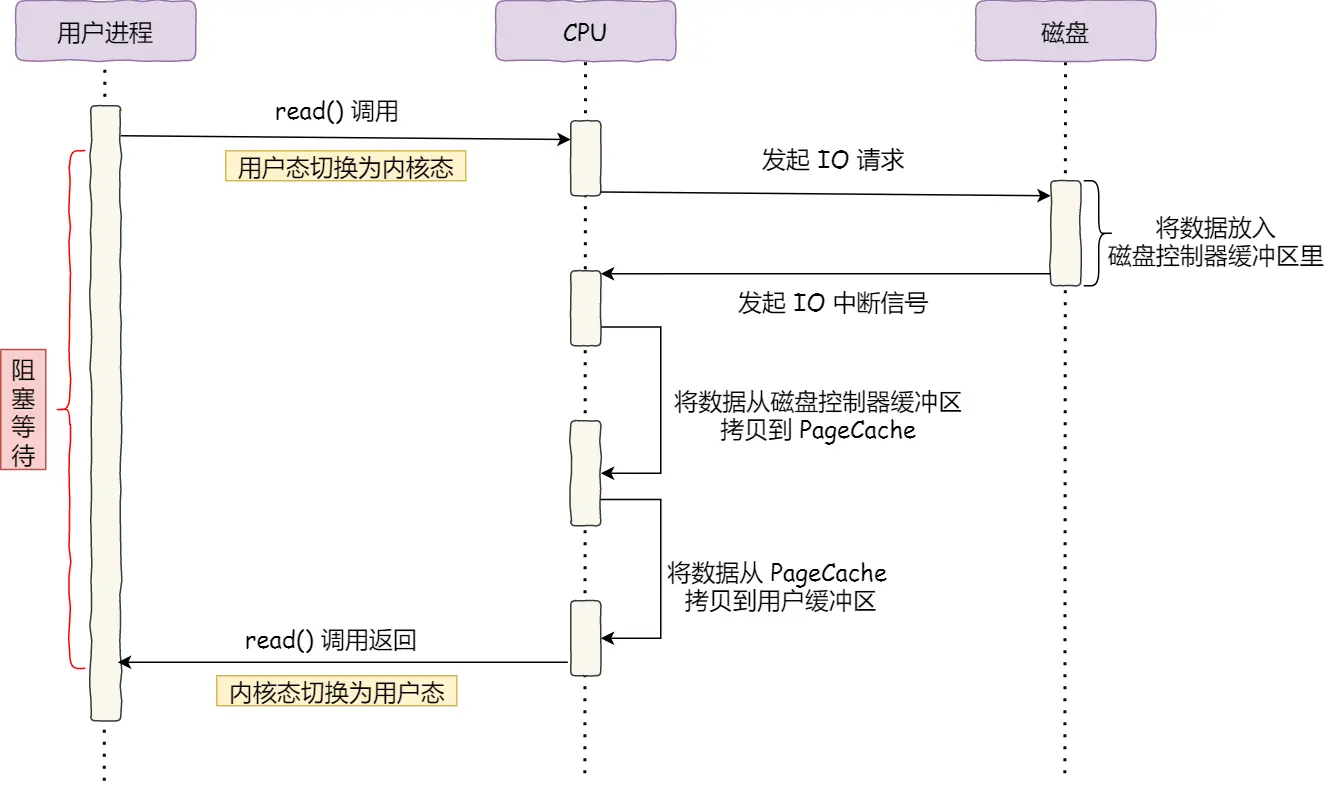
- 用户进程调用read(), 切换到内核态, CPU向磁盘发起IO请求
- 磁盘将数据放入到磁盘控制器缓冲区里面, 发送IO中断信号给CPU
- CPU将数据从磁盘数据控制器缓冲区中拷贝到 PageCache
- CPU将数据从PageCache中拷贝到用户缓冲区
- read()调用返回, 切换到用户态
一共发生了两次用户态和内核态的上下文切换, 发生了两次拷贝, 并且数据的搬运也是交给CPU来操作的, 占用了大量的CPU的时间, 导致了CPU吞吐量下降
解决方式就是引入了DMA(Direct Memory Access)直接内存访问技术,
我们将把数据从磁盘控制器缓冲区搬运到PageCache的工作交给了DMA控制器来进行
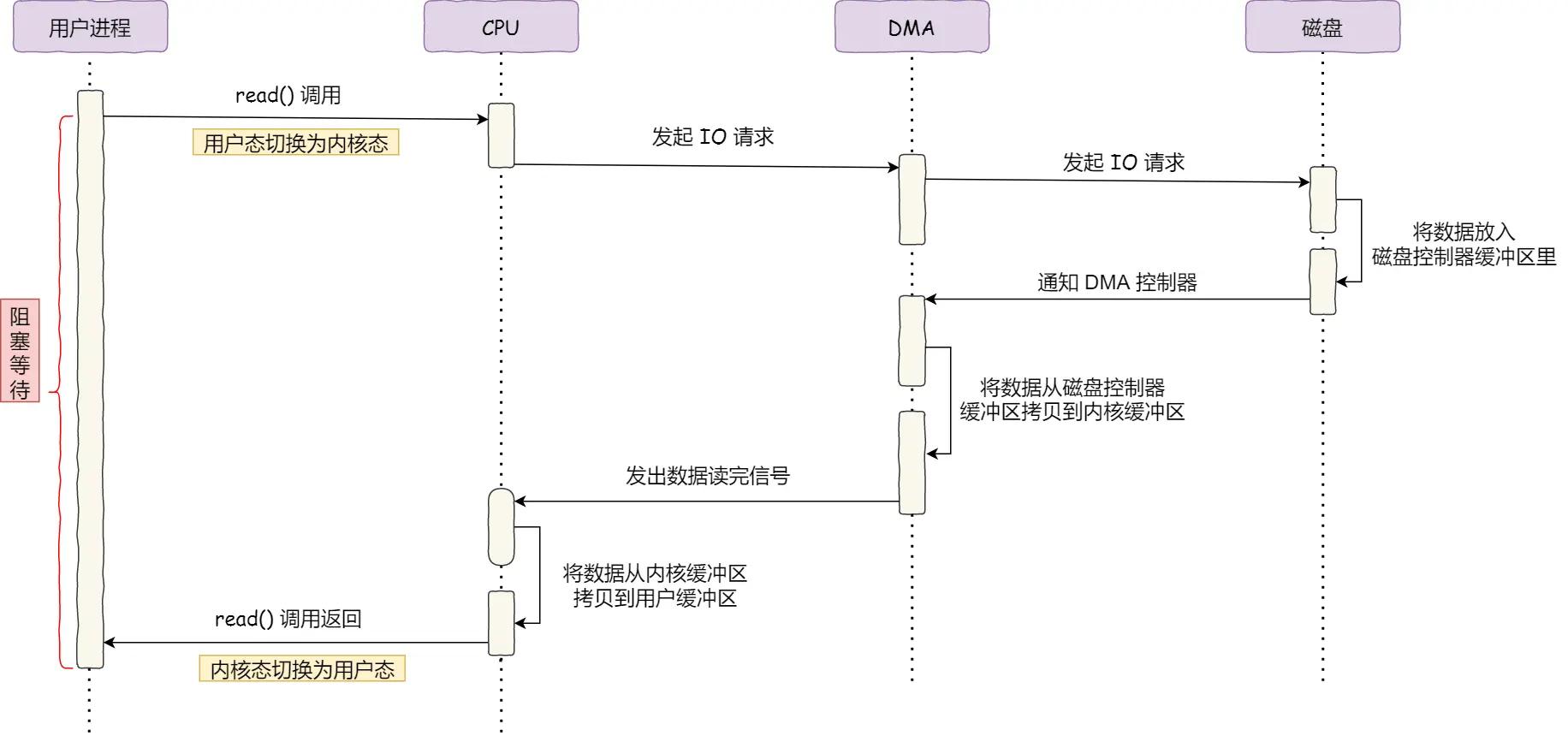
现在的读一个文件的流程变成了
- 用户进程调用read(), 切换到内核态, 向操作系统发起IO请求, 将数据读取到自己的内存缓冲区中, 进程进入到了阻塞状态
- CPU收到操作系统发送的指令以后, 将请求发送给DMA, DMA再进一步发送给磁盘
- 磁盘将数据放入到磁盘控制器缓冲区里面, 发送IO中断信号给DMA控制器, 告知缓冲区已满
- DMA收到磁盘的信号, 将磁盘缓冲区中的数据拷贝到内核缓冲区中, 此时不占用CPU, CPU可以执行其他的任务
- CPU将数据从PageCache中拷贝到用户缓冲区
- read()调用返回, 切换到用户态
零拷贝
我们如果要使用网络传输一个文件, 最初是怎么实现的
我们一般要用到两个系统调用
1 | read(file, tmp_buf, len); |
read读取文件到buf中, write再将这个buf中的内容通过socket发送给客户端, 在这个过程中, 我们会经历四次用户态和内核态的上下文切换, 四次拷贝
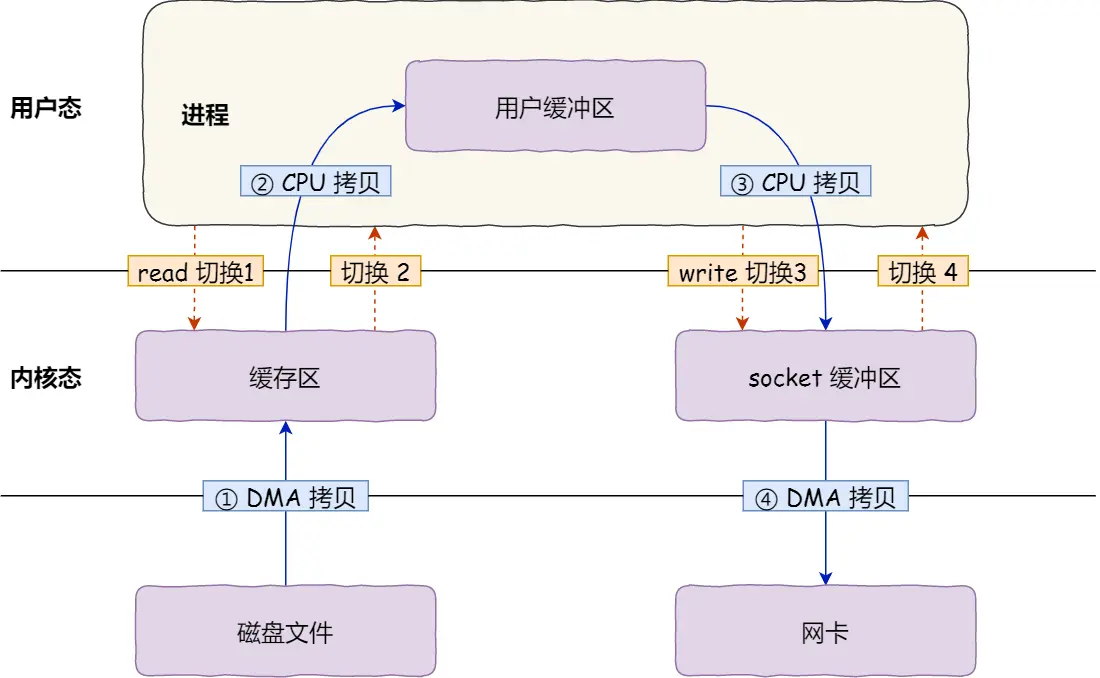
- 用户调用read()系统调用, 切换内核态
- 将文件从磁盘控制器缓冲区DMA拷贝到内核缓冲区
- 将文件从内核缓冲区CPU拷贝到用户缓冲区
- 切换到用户态
- 用户调用write(), 切换到内核态
- 将用户缓冲区中的数据CPU拷贝到socket缓冲区中
- 将socket缓冲区的数据DMA拷贝到网卡中, 发送数据
- 切换回用户态
我们要优化这种IO形式, 关键就在于减少内核态与用户态的上下文切换, 并减少拷贝的次数
怎么减少用户态和内核态的切换, 只要执行了一次系统调用, 不可避免地会有两次切换, 所以核心思路就是减少系统调用的数量
怎么减少拷贝的数量, 在这个文件出书的场景中, 其实用户缓冲区是完全没有必要的存在
mmap + write
使用mmap代替read函数
1 | buf = mmap(file, len); |
mmap系统调用直接把内核缓冲区中的数据映射到用户空间, 这样我们就相当于不使用用户缓冲区中转数据, 减少了一次数据的拷贝
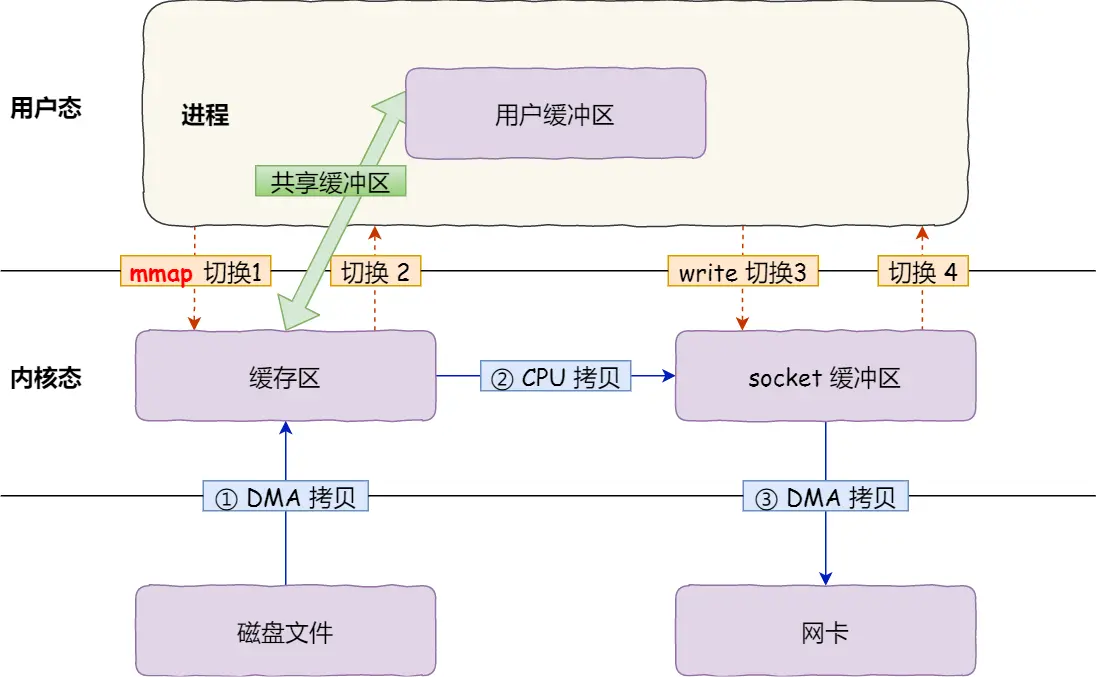
现在PageCache中的数据直接通过CPU拷贝到scoket缓冲区中
但是这种形式系统调用的次数仍然是两次, 也就是内核态和用户态的上下文切换的次数仍然是四次
sendfile
1 |
|
这个系统调用能直接将mmap + write合并, 能减少一次系统调用的次数
并且如果网卡支持SG-DMA技术(The Scatter-Gather Direct Memory Access), 还能再减少一次数据拷贝
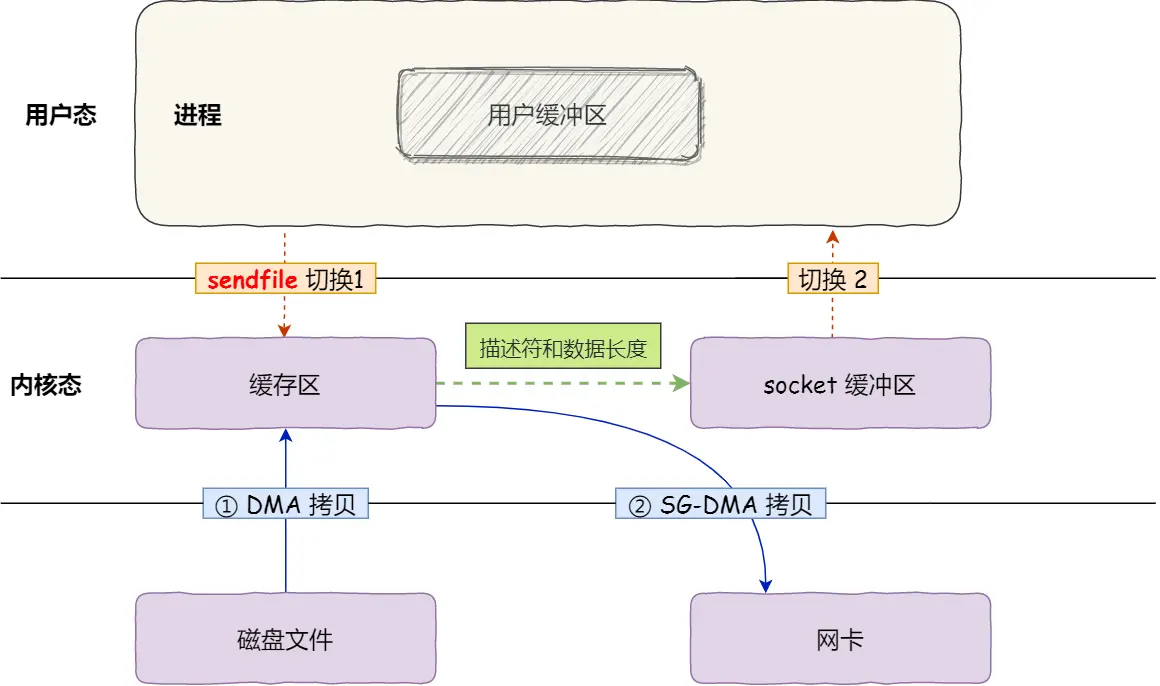
- 通过DMA将磁盘的数据拷贝到内核缓冲区
- 缓冲区描述符和数据长度传到socket缓冲区, 网卡的SG-DMA控制器直接将内核缓存中的数据拷贝到网卡的缓冲区中
省去了将数据从内核缓冲区中拷贝到socket缓冲区中的过程
这样就是零拷贝的最终形态, 只需要两次数据的拷贝, 两次内核态和用户态的上下文切换, 并且没有在内存层面的数据拷贝, 也就是这个过程全程是通过DMA来进行的, 不需要CPU参与
大文件传输实现的特殊性
PageCache
我们常说的IO文件的时候的内核缓冲区, 就是PageCache(磁盘高速缓存). 在零拷贝中我们就使用了PageCache, 读文件时候, 会先将数据通过DMA控制器读到内核缓冲区中. 实际上PageCache就可以看作是磁盘和内存之间的中间层, 和CPU Cache是性质类似的东西
PageCache有预读功能, 同时PageCache内部是一个LRU队列, 会维护热点数据. 如果我们读大文件, 就会导致LRU队列我们批量读取文件的时候的预读失效和缓存污染问题(当然Linux通过inactive_list和active_list以及升级策略很大程度上解决了这个问题).
但是我们还是能很明显看出, 在读大文件的时候PageCache是没有什么作用的,
- 读大文件预读功能没有什么用
- 缓存最近被访问的数据, 大文件导致缓存污染
相当于DMA多做了一次没有的数据拷贝
直接I/O
我们直接绕开DMA, 并且不再拷贝到内核缓冲区中. 阻塞问题我们使用异步I/O来解决
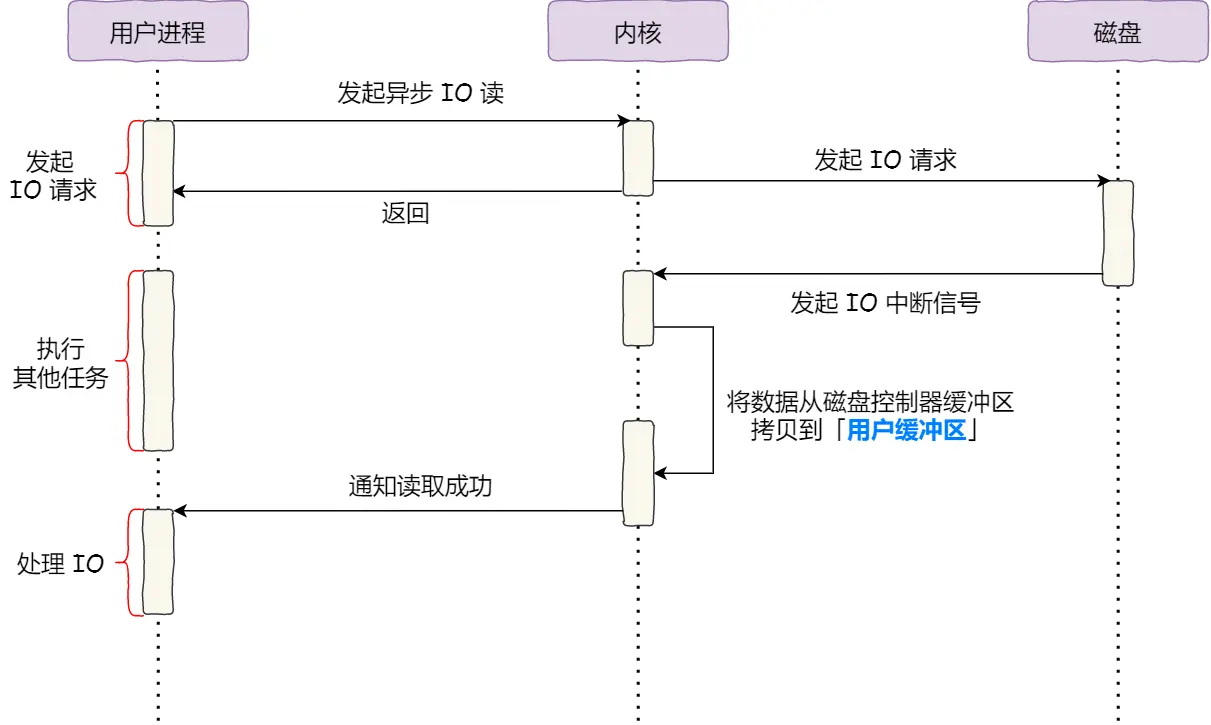
- 用户进程调用系统调用, 发起异步I/O读, CPU发送指令到磁盘, 这里会直接返回, 也就是不阻塞读
- 然后磁盘准备好数据后发送IO中断信号, DMA将数据从磁盘控制器缓冲区拷贝到用户缓冲区
- 通知用户进程读取成功了
直接I/O绕过了PageCache就无法享受到内核提供的两点优化
- 内核的I/O调度算法会缓存尽可能多的I/O请求在PageCache中, 最后合并成一个更大的I/O请求, 减少I/O次数
- 无法享受到预读机制
参考文档: