
Java基础面试问题
Java基础
a = a + b 与 a += b 的区别
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。
1 | byte a = 127; |
(因为 a+b 操作会将 a、b 提升为 int 类型,所以将 int 类型赋值给 byte 就会编译出错)
为什么需要泛型?
适用于多种数据类型执行相同的代码
引入泛型,它将提供类型的约束,提供编译前的检查
泛型方法
泛型方法创建
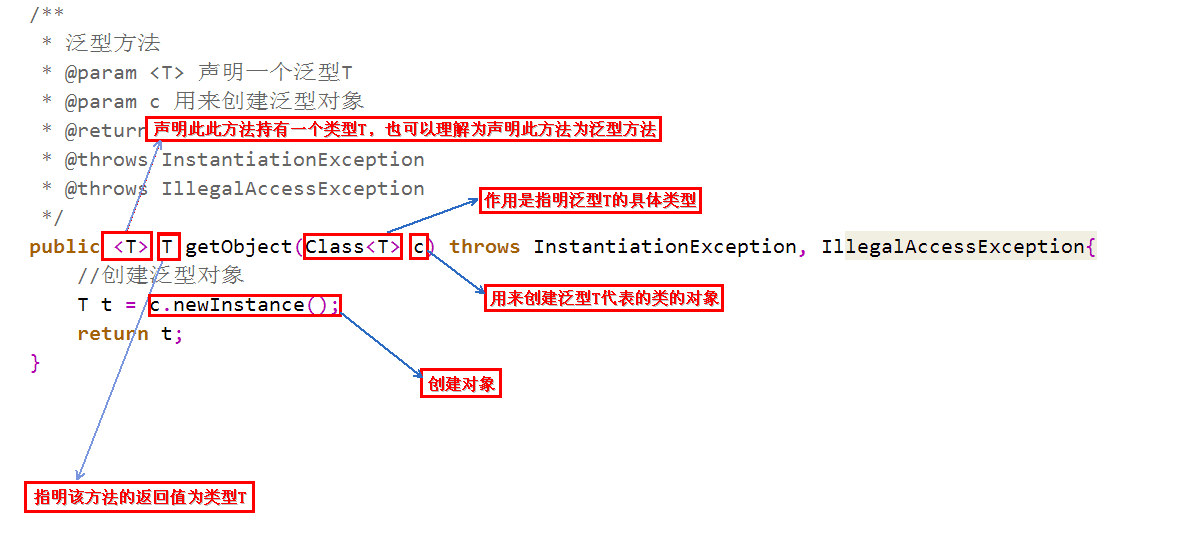
泛型方法使用

泛型方法创建的时候需要使用<T>来声明这是一个泛型方法, 在传入的参数中需要有Class<T> c参数来指明传入的参数的类型, 然后在方法中通过反射newInstance方法来创建一个新的对象
使用泛型方法的时候, 可以通过Class.forName(“全限定类名”)来获取Class类
泛型的上限和下限?
在使用泛型的时候,我们可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。
上限
1 | class Info<T extends Number>{ // 此处泛型只能是数字类型 |
下限
1 | publicstaticvoidfun(Info<? super String> temp){// 只能接收String或Object类型的泛型,String类的父类只有Object类System.out.print(temp +", ");} |
如何理解Java中的泛型是伪泛型?
泛型中类型擦除 Java泛型这个特性是从JDK 1.5才开始加入的,因此为了兼容之前的版本,Java泛型的实现采取了“伪泛型”的策略,即Java在语法上支持泛型,但是在编译阶段会进行所谓的“类型擦除”(Type Erasure),将所有的泛型表示(尖括号中的内容)都替换为具体的类型(其对应的原生态类型, 同时这里是会擦除成下限类型),就像完全没有泛型一样。
注解
元注解,元注解是用于定义注解的注解,包括@Retention、@Target、@Inherited、@Documented
@Retention用于标明注解被保留的阶段@Target用于标明注解使用的范围@Inherited用于标明注解可继承
Java异常类层次结构?
Throwable
是 Java 语言中所有错误与异常的超类。
- Error 类及其子类:程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
- Exception 程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
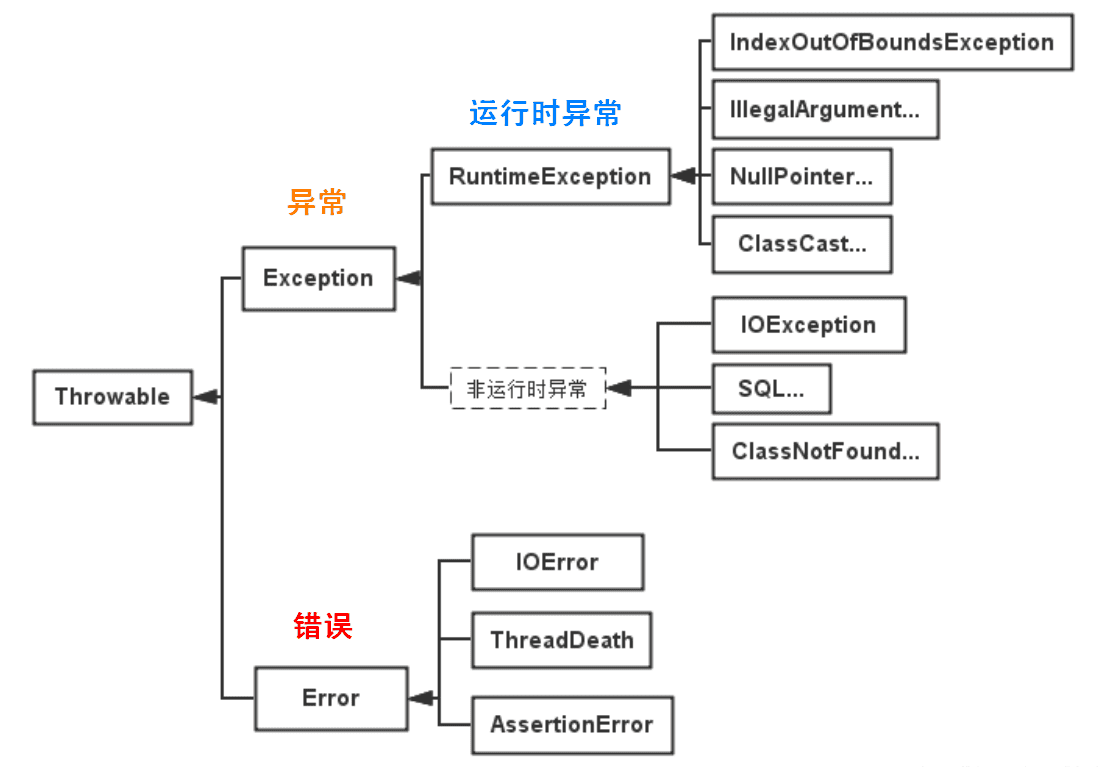
- 运行时异常
都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
- 非运行时异常 (编译异常)
是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)区别?
- 可查异常(编译器要求必须处置的异常):
正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
- 不可查异常(编译器不要求强制处置的异常)
包括运行时异常(RuntimeException与其子类)和错误(Error)
什么是SPI机制?
SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和PostgreSQL都有不同的实现提供给用户,而Java的SPI机制可以为某个接口寻找服务实现。Java中SPI机制主要思想是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要,其核心思想就是 解耦。
SPI整体机制图如下:
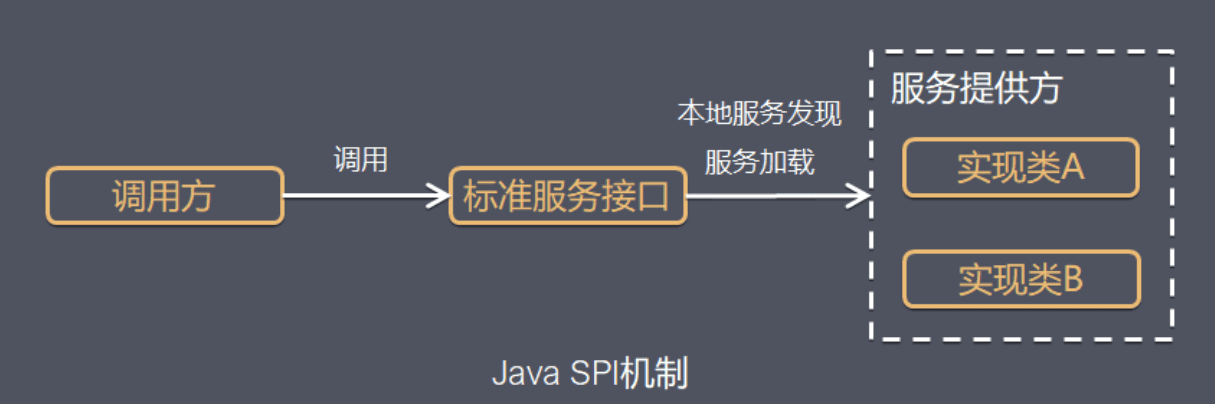
当服务的提供者提供了一种接口的实现之后,需要在classpath下的META-INF/services/目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体的实现类。当其他的程序需要这个服务的时候,就可以通过查找这个jar包(一般都是以jar包做依赖)的META-INF/services/中的配置文件,配置文件中有接口的具体实现类名,可以根据这个类名进行加载实例化,就可以使用该服务了。JDK中查找服务的实现的工具类是:java.util.ServiceLoader。
SPI机制的应用?
- SPI机制 - JDBC DriverManager
在JDBC4.0之前,我们开发有连接数据库的时候,通常会用Class.forName(“com.mysql.jdbc.Driver”)这句先加载数据库相关的驱动,然后再进行获取连接等的操作。而JDBC4.0之后不需要用Class.forName(“com.mysql.jdbc.Driver”)来加载驱动,直接获取连接就可以了,现在这种方式就是使用了Java的SPI扩展机制来实现。
- JDBC接口定义
首先在java中定义了接口java.sql.Driver,并没有具体的实现,具体的实现都是由不同厂商来提供的。
- mysql实现
在mysql的jar包mysql-connector-java-6.0.6.jar中,可以找到META-INF/services目录,该目录下会有一个名字为java.sql.Driver的文件,文件内容是com.mysql.cj.jdbc.Driver,这里面的内容就是针对Java中定义的接口的实现。
- postgresql实现
同样在postgresql的jar包postgresql-42.0.0.jar中,也可以找到同样的配置文件,文件内容是org.postgresql.Driver,这是postgresql对Java的java.sql.Driver的实现。
- 使用方法
上面说了,现在使用SPI扩展来加载具体的驱动,我们在Java中写连接数据库的代码的时候,不需要再使用Class.forName("com.mysql.jdbc.Driver")来加载驱动了,而是直接使用如下代码:
1 | String url = "jdbc:xxxx://xxxx:xxxx/xxxx"; |